0. 책 소개
자료구조 공부도 얼추 끝났고, DFS/BFS와 같은 핵심 아이디어들도 학습하였다.
본격적으로 알고리즘 공부를 위해 선정한 책이 코딩 인터뷰를 위한 알고리즘 치트시트이다.
해당 책은 깃허브 labuladong의 Fucking Alorithm 원어 레포/영어 레포의 번역판이다. 책은 일본어판을 중역한 것으로 생각되고, 실제로 번역이 조금 아쉽긴 하지만 labuladong의 꼼꼼한 풀이가 도움이 되는 것 같다. 본 데이터 스트럭처 시리즈에 이어서 해당 책을 공부하면서 정리해보고자 한다.
말머리는 '뻐킹 알고리즘'으로 지으려다가 취업 시즌이기도 하고...'알고리즘 치트시트'라는 이름으로 지었다. 한편 게시글의 사진은 labuladong의 레포에서 발췌하였고, 코드는 레포에 있는 다양한 언어들의 예시를 chat gpt를 이용해 타입스크립트로 변환하였다.
1. 문제 해결의 아이디어
1. 데이터 구조와 저장 방식
데이터 구조를 다룰 때에는 '순회'와 '접근'의 측면을 핵심으로 볼 필요가 있다. 그리고 이를 '추가, 삭제, 검색, 수정'으로 구체화할 수 있다.
-
연결 리스트와 배열
배열은 확장하는 경우 배열의 복사를 진행하므로 O(N)의 시간 복잡도를 가진다. 연결 리스트는 O(1)의 시간 복잡도를 가지기에 시간 복잡도에서 유리하다. 하지만 더 많은 메모리 공간을 차지하며, 인덱스를 이용한 접근이 불가능하다.
배열 : 추가/삭제- O(N), 검색/수정- O(1)
연결 리스트 : 추가/삭제- O(1) 검색/수정- O(N)
데이터의 추가, 삭제가 빈번한 스택과 큐는 연결리스트가 유리함을 알 수 있다. 하지만 연결리스트가 더 많은 메로리 공간을 차지한다는 점은 염두에 두자. -
그래프
그래프를 표현하는 데에 인접 리스트와 인접 행렬을 사용할 수 있다.
인접 리스트는 메모리 효율이 좋다. 하지만 연산이 많이 든다.
인접 행렬은 메모리 효율이 나쁘다. 하지만 연산이 효율적이다.
2. 데이터 구조의 기본 조작
데이터 구조는 기본적으로 순회와 접근이다.
선형적인 순회와 접근은 for/while을 이용한 반복을 떠올릴 수 있다.
비선형적 방식은 재귀가 대표적이다.
비선형적 순회는 결과적으로 N항 트리를 다루는 문제의 프레임을 갖는다.
모든 알고리즘 문제해결은 알고리즘 문제를 '선형적인 순회'인지, '비선형적 순회'인지를 파악해서 배열, 연결 리스트, 트리라는 프레임으로 해결하는 과정이다.
2. 동적 계획법
최소, 최대값을 구하는 문제는 '무차별 탐색(브루트 포스)'를 통해 풀 수 있다. 브루트 포스는 N항 트리를 통해 푸는 문제로 볼 수 있다.
무차별 탐색의 최적화 과정에서, 각각의 문제를 하위의 문제로 나누고, 이를 '메모' 또는 'DP 테이블'로 최적화하는 것이 동적 계획법이다. 즉 동적 계획법은 '하위 중첩 문제가 있는 무차별 탐색'으로 볼 수 있다.
동적 계획법의 세가지 요소는 아래와 같다
- 하위 중첩 문제
- 최적 하위 구조
- 상태 전이 방정식
상태 전이 방정식(우리나라에선 대충 '점화식'으로 표현되는 그거)를 작성하는 것이 동적 계획법 풀이의 핵심이다. 상태 전이 방정식을 풀기 위해서는 아래의 사항들을 생각해야 한다.
- 이 문제의 Base 케이스는 무엇인가?
- 이 문제는 어떤 '상태'를 갖고 있는가?
- 각 '상태'는 어떤 '선택'을 통해 변화시킬 수 있는가?
- 어떻게 DP배열과 함수를 정의하여 '상태'와 '선택'을 표현하는가?
다시 말해 '상태', '선택', 'DP배열의 정의' 세 가지가 있다.
아래는 동적 계획법에 따라 최대값으로 초기화하는 프레임이다.
//base case 초기화
dp[0][0] = base case
//상태 전이 진행
상태1의모든데이터.forEach((상태1)=>{
상태2의모든데이터.forEach((상태2)=> {
...
dp[상태1][상태2][...] = Math.max(선택1, 선택2, ...)
}
}
1. 피보나치
- 무차별 재귀
대표적인 재귀 문제인 피보나치를 무차별 재귀로 표현하면 아래와 같다.
function fib(N:number):number {
if(N == 0) return 0;
if(N == 1 || N == 2) return 1;
return fib(N - 1) + fib(N - 2)
}
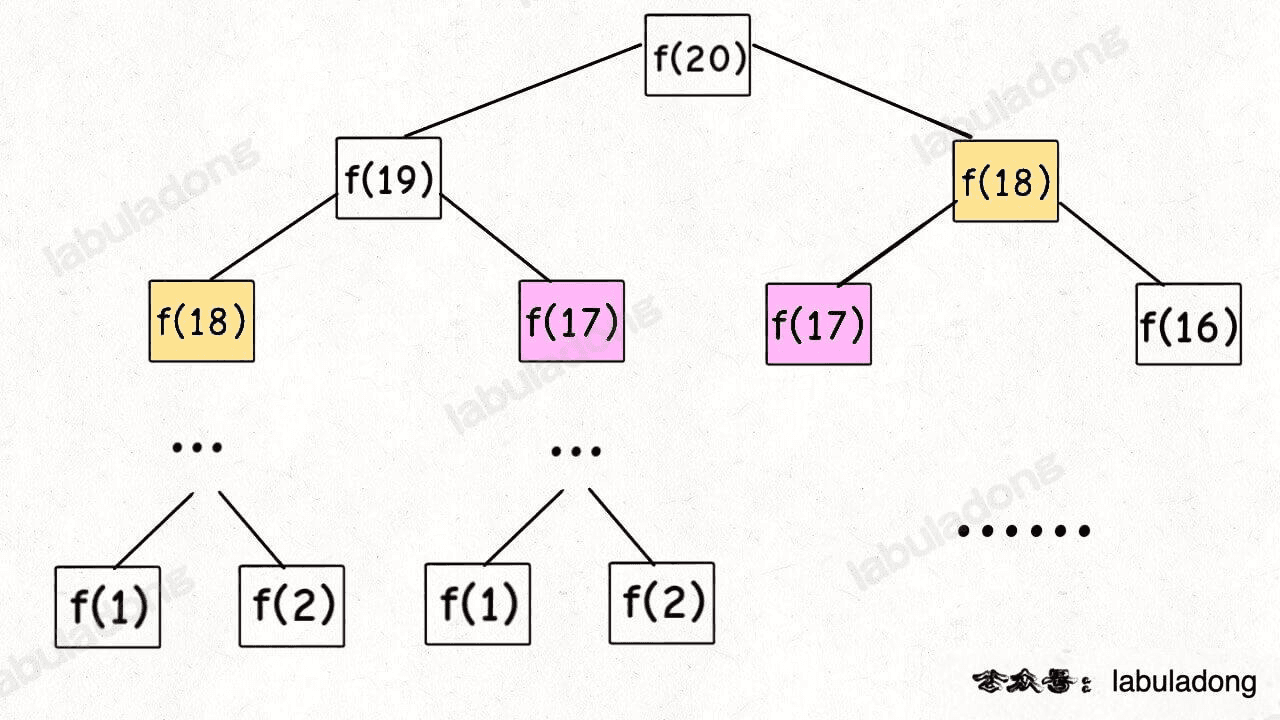
위 코드의 점화식을 그리면 이진 트리가 0, 1, 2까지 쭉 뻗어나간다.
시간 복잡도는 O(2^n)이다.
- 메모를 사용하기
위의 무차별 재귀를 살펴보니 같은 부분문제가 반복적으로 호출됨을 확인할 수 있다.
가령 fio(5)를 해결하기 위해
fib(4), fib(3)이 호출되고,
fib(3), fib(2)와 fib(2), fib(1)이 호출되고
fib(2), fib(1)이 호출된다.
반복적으로 호출되는 것을 해시 테이블에 저장하면 시간복잡도를 낮출 수 있을 것이다.
function fib(N: number): number {
if (N === 0) return 0;
//메모를 모두 초기화
const memo: number[] = new Array(N + 1).fill(0);
// 메모 배열을 갖는 재귀
return helper(memo, N);
}
function helper(memo: number[], n: number): number {
//base case
if (n === 1 || n === 2) return 1;
// 이미 계산된 부분은 반환하기
if (memo[n] !== 0) return memo[n];
//계산되지 않은 부분은 재귀하기
memo[n] = helper(memo, n - 1) + helper(memo, n - 2);
return memo[n];
}
위의 방식을 통해 중복되는 부분을 '가지치기'한다.
fib(5)를 해결하기 위해 fib(4) => fib(3) => fib(2) => fib(1)이 호출될 것이고, 그 이후에 fib(3)이 호출되어 메모 배열의 값을 반환하고 끝난다. 시간 복잡도가 크게 줄어드는 것이다. 시간 복잡도는 노드의 수에 비례하여 증가하므로 O(n)의 시간복잡도를 갖는다.

하향식 / 상향식
큰 문제에서 작은 문제로 계층적으로 내려가 base case까지 내려오는 방식을 탑 다운(하향식)이라고 한다.
위에서 구현한 방식이 탑 다운이며, 이 기법을 '메모이제이션'이라 하고, 해당 배열을 '메모'라 부른다.
base case에서부터 상향식으로 계산하는 방식을 '타뷸레이션'이라 하고, 상향식으로 하나씩 계산해가면서 배열에 값을 채워넣는데, 이 배열을 'DP 테이블'이라 부른다.
하향식은 호출되었을 때에 계산되지만(Lazy-Evaluation)
상향식은 호출되기도 전에 모든 테이블을 계산해둔다.
상향식이 메모리를 더 많이 소모하게 되지만, 일단 완성하면 접근에 O(1)의 시간 복잡도가 걸린다.
아래는 dp테이블을 완성해가며 피보나치를 푸는 문제이다.
function fib(N: number): number {
if (N === 0) return 0;
if (N === 1 || N === 2) return 1;
const dp: number[] = new Array(N+1).fill(0);
// base case
dp[1] = dp[2] = 1;
for(let i = 3; i <= N; i++) {
dp[i] = dp[i-1] + dp[i-2];
}
return dp[N];
}

DP테이블을 사용하지 않고, 순전히 fib(20)을 구하는 것이 목적이라면 아래와 같이 단 두 개의 변수만으로도 문제를 풀 수 있다. 공간복잡도를 O(1)로 최적화하는 것이다.
function fib(N: number): number {
if (N === 0) return 0;
if (N === 1 || N === 2) return 1;
let prev = 1, curr = 1;
for (let i = 3; i <= N; i++) {
let sum = prev + curr;
prev = curr;
curr = sum;
}
return curr;
}
타뷸레이션에서 쓰이는 이 기법을 '상태 압축'이라 하며, 보통 O(N^2)을 O(N)으로 압축한다.
2. 동전 계산하기
리트코드의 대표적인 문제인 DP문제인 동전 교환을 풀어보자. (그리디로 풀 수 있다는 점은 비밀로 하자)
문제 : k 종류의 동전으로 amount의 금액을 만든다. 한 종류의 동전을 여러번 쓸 수 있다.
-
최적 하위 구조를 가지는가? 최적 하위 구조는 하위의 문제가 상호 독립적이다. 가령 '수능 성적'과 '국어, 영어, 수학, 사회1, 사회2, 한국사'라는 각각의 부분 문제들은 상호 독립적이다. 만일 '국어와 수학 성적의 총합은 150이 넘을 수 없다'와 같은 제약조건이 붙으면 최적 하위 구조를 이루지 못한다.
동전 구하기 문제는 '1원'이 존재하여 최적 하위 구조를 이루고 있다. 가령 10원까지의 부분 문제가 해결되면 11원은 '10원까지의 부분문제 + 1원'으로 구할 수 있다. 동전의 갯수에도 제약이 없다. -
상태 전이 방정식을 구상하기
- base case 설정하기 : 0원일 때는 동전이 0개가 필요하다. 0을 base case로 한다.
- 상태 결정하기 : 문제에서 변수는 종류 k, 금액 amount, 동전 수 j이다. 이때 k는 문제에서 주어지고, 동전 수는 제약 조건이 없다. 따라서 상태가 될 수 있는 것은 amount이다.
- 선택 파악하기 : 그래서 amount가 왜 변하는가? 그야 동전을 추가하거나 빼기 때문에 변한다. 앞서 말했듯 추가/제거에는 제약이 없이 자유롭기 때문에 동전의 액면가 k가 선택지가 된다.
- dp 함수와 테이블 정의하기 :
DP함수 : dp(n) - 입력된 값 n에 대해 최소의 동전의 수를 반환한다.
function coinChange(coins: number[], amount: number): number {
const dp = (n: number): number => {
// base case
if (n === 0) return 0;
if (n < 0) return -1;
// to minimize it is to initialize it to infinity
let res = Infinity;
for (let coin of coins) {
const subproblem = dp(n - coin);
// No solution to subproblem, skip
if (subproblem === -1) continue;
res = Math.min(res, 1 + subproblem);
}
return res !== Infinity ? res : -1;
};
return dp(amount);
}
시간 복잡도는 O(n^k)이다. 메모 테이블로 시간 복잡도를 낮추자.
function coinChange(coins: number[], amount: number): number {
// memo
const memo = new Map<number, number>();
const dp = (n: number): number => {
// Check the memo to avoid double counting
if (memo.has(n)) return memo.get(n)!;
//base case
if (n === 0) return 0;
if (n < 0) return -1;
let res = Infinity;
for (let coin of coins) {
const subproblem = dp(n - coin);
if (subproblem === -1) continue;
res = Math.min(res, 1 + subproblem);
}
// note on memo
memo.set(n, res !== Infinity ? res : -1);
return memo.get(n)!;
};
return dp(amount);
}
상향식으로 접근할 때에는 아래와 같이 DP 테이블을 정의하고 채워나갈 수 있다.
DP 테이블 : 목표 금액이 i일 때에 최소 dp[i]개의 동전을 필요로 한다.
function coinChange(coins: number[], amount: number): number {
// The array size is amount + 1 and the initial value is also amount + 1
// dp[amount]를 조회하기 위해 배열의 길이를 amount + 1로 설정함.
// 가질 수 있는 최대의 동전 갯수가 amount이므로, 모든 배열인 이보다 1 큰 값인 amount + 1로 초기화함.
const dp = new Array(amount + 1).fill(amount + 1);
// base case
dp[0] = 0;
for (let i = 0; i < dp.length; i++) {
// The inner for is finding the minimum of + 1 for all subproblems
for (let coin of coins) {
// No solution to subproblem, skip
if (i - coin < 0) continue;
dp[i] = Math.min(dp[i], 1 + dp[i - coin]);
}
}
return dp[amount] === amount + 1 ? -1 : dp[amount];
}
결론
DP 문제는
- 어떻게 무차별 탐색을 완수할 것인가? (무엇을 선택하여 어떤 상태를 변화시킬 것인가?)
- 어떻게 똑똑하고 효율적으로 완수할 것인가? ("memo" 또는 "dp table"로 어떻게 시간/공간 복잡성을 줄일 것인가)
에 대한 문제를 다룬다.
3. 역추적 (백트래킹)
'백트래킹' 이라는 고급진 이름을 가지고 있지만, 무차별 탐색에서 '선택 해제'가 추가되었을 뿐이다.
백트래킹은 아래의 3가지를 고려하여 '순회'하게 된다.
- 경로 : 이미 선택된 놈들
- 선택 리스트 : 현재에서 할 수 있는 선택들
- 종료 조건 : 의사 결정 트리 하부에 도달하여 더 이상 선택할 수 없는 조건
백트래킹은 재귀로 호출되며 아래와 같이 의사코드를 짤 수 있다.
function beacktrack(경로, 선택 리스트){
if (종료조건===true) return result.add(경로)
for (선택 in 선택 리스트) {
backtrack(경로+선택, 선택 리스트 - 선택)
선택 해제
}
def backtrack(Path, Seletion List ):
if meet the End Conditon:
result.add(Path)
return
for seletion in Seletion List:
select
backtrack(Path, Seletion List)
deselect
1. 순열 문제
순열 : 서로 다른 n개의 원소에서 r개를 중복없이 순서에 상관있게 선택하는 혹은 나열하는 것. 경우의 수는 nPr이다.
1, 2, 3 세 개의 원소에서 3개를 순서에 상관 있게 나열하는 경우의 수는 n!이다.
순열을 손으로 직접 그려가면
null을 루트로 하고, 1, 2, 3이 각각 자식인 트리가 그려질 것이다.

이때 이미 선택된 부모 노드들이 경로, 선택할 수 있는 자식 노드들이 선택이다.

이때 순회를 마치면 경로를 한 단계 거슬러 올라갈 것이다. 이것이 선택 해제이다.

트리의 순회로 이를 파악하면, 'select' 과정은 전위순회로 이루어지며, 'deselect'과정은 후위 순회로 이루어진다.

순열의 예제에서 제약조건이 없이 순회하는 경우, 순회 순서는 트리에서의 '전위 순회'와 정확하게 일치하게 된다.
[
[1,1,1],[1,1,2],[1,1,3],[1,2,1],[1,2,2],[1,2,3],[1,3,1],[1,3,2],[1,3,3],
[2,1,1],[2,1,2],[2,1,3],[2,2,1],[2,2,2],[2,2,3],[2,3,1],[2,3,2],[2,3,3],
[3,1,1],[3,1,2],[3,1,3],[3,2,1],[3,2,2],[3,2,3],[3,3,1],[3,3,2],[3,3,3]
]
이때 '중복된 숫자를 선택할 수 없다'는 제약조건에 따라 순회를 중단하고 후위 순회의 순서로 돌아가는 것이다.

// 조합 / 부분 집합 문제 백트래킹 알고리즘 프레임 워크
const backtrackCombination = (nums: number[], start: number, track: number[]): void => {
// 백트래킹 알고리즘 표준 프레임 워크
for (let i = start; i < nums.length; i++) {
// 선택
track.push(nums[i]);
// 매개변수 유의
backtrackCombination(nums, i + 1, track);
// 선택 취소
track.pop();
}
}
// 순열 문제 백트래킹 알고리즘 프레임 워크
const backtrackPermutation = (nums: number[], used: boolean[], track: number[]): void => {
for (let i = 0; i < nums.length; i++) {
// 가지치기 로직
if (used[i]) {
continue;
}
// 선택
used[i] = true;
track.push(nums[i]);
backtrackPermutation(nums, used, track);
// 선택 취소
track.pop();
used[i] = false;
}
}
2. N-퀸 문제
리트코드 51. N-Queens
체스에서 퀸은 상,하,좌,우,대각선의 8방향으로 모두 직선이동할 수 있다.
퀸이 서로를 위협하지 않도록 체스판 위에 놓는 문제이다.
문제 : 체스판이 n*n의 체스판 위에 n개의 퀸을 놓는 모든 경우의 수를 문자열 배열로 출력하라. 퀸이 놓이지 않은 칸은 .으로 출력한다.
Input: n = 4
Output: [[".Q..","...Q","Q...","..Q."],["..Q.","Q...","...Q",".Q.."]]
문제 풀이는 다음과 같다.
- 한 자리에 퀸을 놓는다. (주로 좌측 상단부터 놓는다.)
- 그 다음 자리를 선택한다. 퀸을 놓을 수 없다면 선택을 해제한다.
1과 2를 반복한다. 2에서 이루어지는 과정이 바로 백트래킹이다.

백트래킹의 원리를 이용하여 모든 경우의 수를 구하는 점을 제외하면 나머지 디테일에서 차이가 있을 수 있다. n*n개의 체스판을 모두 탐색해도 되지만, 아래와 같은 디테일을 생각해볼 수 있다.
- 한 행에는 하나의 퀸만 놓일 수 있다. (퀸은 좌 우를 직선공격 할 수 있기 때문.)
- 대각선을 탐색할 때에는 대각선 위 방향으로 탐색한다. 위의 행부터 배치했기 때문에 아래 행에는 아직 퀸이 없다.
let res: string[][] = [];
/* 보드의 길이 n을 입력하면 모든 유효한 배치를 반환합니다. */
function solveNQueens(n: number): string[][] {
// '.'는 빈 칸을 의미하고 'Q'는 퀸을 의미합니다. 빈 체스판를 초기화합니다.
let board: string[][] = Array.from({ length: n }, () =>
Array.from({ length: n }, () => ".")
);
backtrack(board, 0);
return res;
}
// 경로: 현재까지 퀸이 배치된 행보다 작은 행에는 이미 퀸이 배치되어 있습니다.
// 선택 리스트: 'row' 행의 모든 열은 퀸의 선택입니다.
// 종료 조건: 행이 체스판의 마지막 줄(n)에 도달합니다.
function backtrack(board: string[][], row: number): void {
// 종료 조건을 만족시킵니다.
if (row === board.length) {
res.push([...board.map((row) => row.join(""))]);
return;
}
const n = board[row].length;
for (let col = 0; col < n; col++) {
// 유효한 선택이 아닌 경우 제외합니다.
if (!isValid(board, row, col)) continue;
// 선택합니다.
board[row][col] = "Q";
// 다음 행으로 진행합니다.
backtrack(board, row + 1);
// 선택을 취소합니다.
board[row][col] = ".";
}
}
function isValid(board: string[][], row: number, col: number): boolean {
const n = board.length;
// 같은 열에 퀸이 있는지 확인합니다.
for (let i = 0; i < row; i++) {
if (board[i][col] === "Q") {
return false;
}
}
// 좌측 상단 대각선에 퀸이 있는지 확인합니다.
for (let i = row - 1, j = col - 1; i >= 0 && j >= 0; i--, j--) {
if (board[i][j] === "Q") {
return false;
}
}
// 우측 상단 대각선에 퀸이 있는지 확인합니다.
for (let i = row - 1, j = col + 1; i >= 0 && j < n; i--, j++) {
if (board[i][j] === "Q") {
return false;
}
}
return true;
}
참고로 n퀸 문제의 시간 복잡도는 O(n^n+1)이다.

결론
백트래킹은
- 경로 : 현재까지 선택된 경우들
- 선택리스트 : 앞으로 선택할 수 있는 경우들
을 유지하는 것이 중요하다. 그리고 - 종료 조건: 문제에서 주어진 목적의 달성가능 여부
목적이 달성되면 결과 Set에 기록한다.
DP문제에서 '상태', '선택', 'base case'가 있었던 점을 상기해보자.
DP문제는 '상태'라는 경로를 '선택'으로 바꾸고 'base case'라는 종료조건을 만나면 종료되는 '백트래킹'으로 대응될 수 있다.
즉 DP문제에서 '무차별 탐색'을 수행하며 '가지치기'를 하는 행위가 곧 백트래킹이라 할 수 있다. 만일 DP문제를 풀이하는 데에 어려움을 겪는다면, 특히 명확한 상태 전이 방정식이 떠오르지 않는 경우 백트래킹을 이용한 풀이를 고려해볼 수 있다.
하지만 반대로 '백트래킹' 문제를 DP로 풀이하는 것은 불가능할 수 있다. 위에서 예시를 든 모든 경우의 수 문제들은 'overlapping subproblems(중복 하위 문제)'가 없다. 이들은 DP로 풀이할 수 없으며, 시간 복잡도가 높은 경향이 있다.
4. BFS 알고리즘
백트래킹 알고리즘은 DFS에 포함된다. 대부분의 DFS 풀이가 백트래킹이다.
BFS알고리즘은 DFS와 달리 사방팔방 확산하면서 탐색한다.
BFS가 DFS와 구분되는 프레임은
- visited는 DFS와 마찬가지로 있다.
- 스택이 없다. 대신 큐가 있다.
- 부모노드 자식노드 같은건 없다. 대신 인접한 노드를 큐에다가 왕창 때려박는다.
인접한 노드를 왕창 때려 박아서 뭘 찾을 수 있나? 최단 경로를 찾을 수 있다.
BFS는 인접한 노드들을 확산해가며 탐색한다. Target을 마주했을 때의 그 깊이가 Start로부터의 최단 경로이다.
최단 경로를 찾는 것이 BFS의 핵심이다.
매우 단순해보이지만 여러가지 변형이 있을 수 있다.
가령 어떤 조작을 하여 목표하는 문자열을 만들고 싶다면?
'어떤 조작'이 경로고
'어떤 조작'으로 만들어지는 경우의 수들이 노드이다.
최초로 목표를 찾았을 때에 행한 '어떤 조작'의 횟수가 바로 최단경로이다. 이 아이디어는 다익스트라 알고리즘에서 활용된다.
아래는 기본적인 BFS 알고리즘의 프레임이다.
const BFS = (start: any, target: any): number => {
const q: any[] = []; // 핵심 자료 구조
const visited = new Set(); // 중복 방지
q.push(start); // 시작 노드 큐에 삽입
visited.add(start);
let step = 0; // 확산 단계 기록
while (q.length !== 0) {
const sz = q.length;
// 현재 큐에 있는 모든 노드 확산
for (let i = 0; i < sz; i++) {
const cur = q.shift();
// 목적지에 도달했는지 확인
if (cur === target) return step;
// 현재 노드와 인접한 노드를 큐에 삽입
for (const x of cur.adj()) {
if (!visited.has(x)) {
q.push(x);
visited.add(x);
}
}
}
// 확산 단계 업데이트
step++;
}
return -1; // 목적지에 도달할 수 없음
};
BFS vs DFS
-
DFS는 최단 경로를 찾을 수 없나? 찾을 수 있다. 하지만 DFS는 모든 경로를 탐색하고 나서야 무엇이 최단경로인지를 파악할 수 있다. 반면 BFS는 최초로 목적지에 도달한 순간이 최단 경로를 통해 도착한 순간이다. 따라서 일반적으로 (둘 모두 O(n)의 시간복잡도를 가지고 있음에도) BFS가 최단경로를 찾는데에 효율적이다.
-
DFS가 어떤 점에서 좋나? BFS는 큐를 사용한다. 전부 큐에 때려박는다. 만일 이진트리 문제를 푼다고 하면 큐에 필요한 최대 공간은 트리의 제일 아래 계층인 O(N/2)가 될 것이다. 반면 DFS는 이진트리의 높이 만큼 스택이 필요하다. O(log n)만큼의 공간 복잡도가 필요한 것이다.
보통 BFS는 최단 경로를 찾을 때에 사용한다. 하지만 많은 경우 DFS를 사용하게 된다. 재귀 함수를 잘 이해하고 있다면 DFS로 구현하는 것이 더 간결한 코드가 나오는 경향도 있고.
1. 좌물쇠를 여는 최소 단계
0부터 9까지의 숫자 4개로 조합된 비밀번호가 있다.
다이얼을 돌려 한 숫자를 1씩 변경할 수 있을 때,
0000에서 시작하여 목표로하는 비밀번호까지 찾는 최소의 변경 횟수를 출력하라.
그런데 이제 제약 조건을 곁들인...
'deadends'에 포함되는 숫자에 다다르면 좌물쇠가 고장난다. deadends에 도달하지 않으면서 타겟을 만드는 최소의 변경횟수를 출력하고, 타겟을 만들지 못하는 경우 -1을 출력한다.
Input: deadends = ["0201","0101","0102","1212","2002"], target = "0202"
Output: 6
위 문제는 deadends를 피하는 방법에 대해 떠올려야 한다. (다행히 문제에서 친절히 설명해준다.)
0202에 다다르면서 deadend를 피하려면 가장 먼저 앞을 1로 만든다. 1000 상태에서 시작하면 1202를 만들 수 있고, 가장 앞을 0으로 되돌리면 0202로 deadend를 우회할 수 있다.
이제 코드를 짜보자
제약 조건이 없는 경우
위의 BFS 프레임을 이용하여 한 칸씩 다이얼을 돌리는 BFS 코드를 짜보자
// s[j]를 한 번 눌러서 1을 더한다.
const plusOne = (s: string, j: number): string => {
const ch = s.split("");
if (ch[j] === "9") {
ch[j] = "0";
} else {
ch[j] = String.fromCharCode(ch[j].charCodeAt(0) + 1);
}
return ch.join("");
};
// s[j]를 한 번 눌러서 1을 뺀다.
const minusOne = (s: string, j: number): string => {
const ch = s.split("");
if (ch[j] === "0") {
ch[j] = "9";
} else {
ch[j] = String.fromCharCode(ch[j].charCodeAt(0) - 1);
}
return ch.join("");
};
// BFS 프레임워크를 사용하여 가능한 모든 비밀번호를 출력한다.
const BFS = (target: string): void => {
const q: string[] = ["0000"];
while (q.length > 0) {
const sz = q.length;
// 현재 큐에 있는 모든 노드를 확산시킨다.
for (let i = 0; i < sz; i++) {
const cur = q.shift()!;
// 도착 지점에 도달했는지 확인한다.
console.log(cur);
// 한 노드의 이웃 노드를 큐에 추가한다.
for (let j = 0; j < 4; j++) {
const up = plusOne(cur, j);
const down = minusOne(cur, j);
q.push(up);
q.push(down);
}
}
// 여기에 단계를 추가한다.
}
return;
};
제약조건 추가 하기
위의 코드에서 다음의 제약조건들이 필요하다.
- 이미 만들었던 조합을 다시 방문하면서 무한루프가 생길 수 있다. visited 셋으로 이를 방지할 수 있다.
- target를 찾으면 다이얼 횟수를 반환하고 반복문를 종료한다.
- 만일 deadend에 속한 문자라면 인접한 노드를 큐에 넣지 않는다.
아래는 타입스크립트 코드이다. (이때 const cur: string | undefined = q.shift();에서 비 null 단언 연산자 '!'를 이용하여 const cur: string = q.shift()!;로 표현하고 있다.)
function openLock(deadends: string[], target: string): number {
// 필요한 데드 엔드 비밀번호 기록
const deads: Set<string> = new Set(deadends);
// 이미 탐색한 비밀번호를 기록하여 되돌아가지 않도록 합니다.
const visited: Set<string> = new Set();
const q: string[] = [];
// 시작점부터 너비 우선 탐색을 시작합니다.
let step: number = 0;
q.push("0000");
visited.add("0000");
while (q.length > 0) {
const sz: number = q.length;
/* 현재 큐에 있는 모든 노드를 주변으로 확장합니다. */
for (let i = 0; i < sz; i++) {
const cur: string = q.shift()!;
/* 도착점에 도달했는지 확인합니다. */
if (deads.has(cur)) continue;
if (cur === target) return step;
/* 미방문 상태인 인접한 노드를 큐에 추가합니다. */
for (let j = 0; j < 4; j++) {
const up: string = plusOne(cur, j);
if (!visited.has(up)) {
q.push(up);
visited.add(up);
}
const down: string = minusOne(cur, j);
if (!visited.has(down)) {
q.push(down);
visited.add(down);
}
}
}
/* 단계 수를 여기에서 추가합니다. */
step++;
}
// 모든 탐색이 끝나도 목표 비밀번호를 찾을 수 없으면 -1을 반환합니다.
return -1;
}
function plusOne(s: string, j: number): string {
const arr: string[] = s.split("");
if (arr[j] === "9") arr[j] = "0";
else arr[j] = (parseInt(arr[j]) + 1).toString();
return arr.join("");
}
function minusOne(s: string, j: number): string {
const arr: string[] = s.split("");
if (arr[j] === "0") arr[j] = "9";
else arr[j] = (parseInt(arr[j]) - 1).toString();
return arr.join("");
}
양방향 BFS
시작지점에서 뻗어나가는 것 뿐만 아니라 끝 지점에서도 함께 뻗어나가면 비교적 빠르게 답을 찾을 수 있다.
경우의 수가 점점 늘어나는 탐색이라면

일반적으로 위와 같겠지만
양방향으로 BFS를 수행하면

위와 같이 일부 케이스를 탐색하지 않고 넘어간다.
끝 점의 위치를 모르면 양방향 탐색을 할 수 없다.
하지만 좌물쇠 문제는 순환 구조이고 끝 점이 명확하므로 양방향을 적용할 수 있다.
아래는 시작지점과 종료지점이 교대로 확산하도록 하여 양방향을 탐색하는 예이다. 큐 대신 set의 size를 이용하고 있다.
// deadends 문자열 배열에 있는 문자열을 모두 HashSet에 추가한다.
const openLock = (deadends: string[], target: string): number => {
const deads: Set<string> = new Set(deadends);
// HashSet은 원소의 존재 여부를 빠르게 판단할 수 있기 때문에 큐 대신 사용할 수 있다.
const q1: Set<string> = new Set();
const q2: Set<string> = new Set();
const visited: Set<string> = new Set();
let step: number = 0;
q1.add("0000");
q2.add(target);
while (q1.size > 0 && q2.size > 0) {
// HashSet은 직접 수정할 수 없기 때문에, temp를 사용하여 새로운 결과를 저장한다.
const temp: Set<string> = new Set();
/* q1의 모든 노드를 확산한다. */
for (const cur of q1) {
/* 도착 지점에 도달했는지 확인 */
if (deads.has(cur)) {
continue;
}
if (q2.has(cur)) {
return step;
}
visited.add(cur);
/* 노드의 방문하지 않은 인접 노드를 추가한다. */
for (let j = 0; j < 4; j++) {
const up: string = plusOne(cur, j);
if (!visited.has(up)) {
temp.add(up);
}
const down: string = minusOne(cur, j);
if (!visited.has(down)) {
temp.add(down);
}
}
}
/* 여기서 단계를 늘린다. */
step++;
// temp는 q1과 같다.
// 다음 while 루프에서는 q2를 확산한다.
q1 = q2;
q2 = temp;
}
return -1;
};
// 문자열의 i번째 자리를 1 증가시키고 문자열을 반환한다.
const plusOne = (s: string, i: number): string => {
const ch: string[] = s.split("");
if (ch[i] === "9") {
ch[i] = "0";
} else {
ch[i] = (parseInt(ch[i]) + 1).toString();
}
return ch.join("");
};
// 문자열의 i번째 자리를 1 감소시키고 문자열을 반환한다.
const minusOne = (s: string, i: number): string => {
const ch: string[] = s.split("");
if (ch[i] === "0") {
ch[i] = "9";
} else {
ch[i] = (parseInt(ch[i]) - 1).toString();
}
return ch.join("");
};
추가로 최적화를 위해 아래와 같은 조건을 추가할 수도 있다.
// ...
while (!q1.isEmpty() && !q2.isEmpty()) {
if (q1.size() > q2.size()) {
// 交换 q1 和 q2
temp = q1;
q1 = q2;
q2 = temp;
}
// ...
시작지점에서 퍼진 경로와 끝지점에서 퍼진 경로 중 더 적은 쪽을 선택하여 확산을 균형있게하고, 이를 통해 공간 복잡도를 줄이는 것이다. (대신 빅O는 같다.)
5. 투 포인터
포인터는 C언어 등에서 변수의 메모리 주소를 저장하는 공간을 의미한다.
투 포인터 기법은 배열에서 두 개의 요소를 지정하여 두 값을 비교하는 방식이다.
매우 효율적인데
- 시간 복잡도가 O(n)이다. '서로 다른 두 값들을 비교하라'고 하는 경우, 선형탐색은 두 개의 반복문이 사용되어 O(n^2)이다.
- 배열이 n일때 공간복잡도가 O(n)이다. 배열 n과 두 포인터를 저장할 2개의 변수만 있으면 된다.
Slow, Fast 포인터
연결 리스트로 된 그래프를 상상해보자.
해당 리스트에 사이클이 있는지 어떻게 판별할 것인가?
1. 싸이클 판별(Floyd's Cycle Detection)
Slow 포인터는 next 연산을 한 번 실행한다.
Fast 포인터는 next 연산을 두 번 실행한다.
만일 사이클이 존재한다면 Slow 포인터와 Fast 포인터는 언젠가 만나게 된다.

위와 같이 싸이클이 있는 단순 연결 리스트가 있다고 해보자.
Slow Pointer: 0-1-2-3-4-5-6-7-8
Fast Pointer: 0-2-4-6-8-6-8-6-8
8번의 이동을 통해, 9번째 노드에서 둘은 만나게 된다.
2. 싸이클 기점 판별
참고
그렇다면 수학적인 넌센스 퀴즈를 풀어보자.
싸이클이 어디서 발생했는지를 어떻게 알까?
싸이클이 판별된 시점에서,
두 포인터 중 하나를 Head로 이동시킨 후,
같은 속도로 이동을 진행하면 된다.
Slow Pointer: 8-9-6-7-8-9-6
Fast Pointer: 0-1-2-3-4-5-6
이렇게 하면 6에서 만나게 되고, 공교롭게도 이 곳이 사이클의 기점이다.
수학적 원리는 아래와 같다.
let,
x = Linked List의 시작과 주기의 시작 사이의 거리.
y = 주기 시작부터 slowPointer 와 fastPointer가 처음 만나는 지점까지의 거리.
l = 사이클의 총 거리.
기점에서 만나기 전까지,
Slow Pointer는 x + s*l + y만큼을 이동했다.
Fast Pointer는 x + f*l + y만큼을 이동했다.
Fast Pointer가 이동한 거리는 Slow Pointer가 이동한 거리의 두 배이다.
따라서 아래와 같은 등식이 나온다.
x + f*l + y = 2(x + s*l + y)
위의 등식을 전개하면
x + y = (f-2s)l
x = (f-2s)l - y
이때 (f-2s)를 임의의 음이 아닌 정수 k로 치환하면,
x = kl - y로 표현할 수 있다.
Head에서 출발한 포인터를 Fast Pointer
교점에서 출발한 포인터를 Slow Pointer라고 가정할 때,
Fast Pointer가 x만큼 이동하여 기점에 도착한다.
그 사이 Slow Pointer도 같은 거리를 이동하므로 kl - y 만큼 이동한다.
이때 Slow Pointer는 사이클에서 이미 y만큼을 이동한 상태였다. kl - y + y는 kl, 즉 Slow Pointer도 즉 기점에서 출발해 k바퀴를 돈 후 기점으로 도착한 것과 같은 결과를 지니게 된다.

Fast Pointer와 Slow Pointer가 모두 기점에 도착하게 되었다.
3. 연결 리스트의 중앙점 찾기
간단하다. fast노드가 tail이 되었을 때 slow node의 위치가 중앙이 된다.
while (fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
}
// "slow" is in the middle
return slow;
이때 연결 리스트의 길이가 짝수인 경우에는 가운데에서 오른쪽으로 위치해있다.
(10의 중앙을 5로 하는 것과 다르게 위의 알고리즘은 10의 중앙을 6으로 하게 된다는 얘기.)

4. 뒤에서 k번째 요소 찾기
단일 연결리스트에서 뒤에서 k번째 요소를 어떻게 찾을까?
fast 포인터를 k에 위치시킨다.
이후 slow포인터와 fast포인터를 한 칸씩 이동시키다가 fast포인터가 tail이 되었을 때, slow 포인터의 위치가 뒤에서 k번째 위치이다.

left, right 투 포인터
left는 0번 인덱스, right는 size-1번 인덱스(혹은 1번 인덱스) 포인터로 초기화한다.
| slow, fast | left, right | |
|---|---|---|
| 사용처 | 단순 연결 리스트 | 배열, 이중 연결 리스트 |
| 포인터 방향 | 같은 방향으로 진행 | 반대 방향으로 진행 |
이진탐색
이진 탐색은 left, right 포인터를 사용하는 대표적인 알고리즘이다. mid라는 세번째 포인터를 사용하여 탐색 범위를 좁히며, O(log N)의 시간 복잡도를 갖게 된다.
// 이진 검색 함수
function binarySearch(nums: number[], target: number): number {
let left: number = 0; // 시작 인덱스
let right: number = nums.length - 1; // 끝 인덱스
// 시작 인덱스와 끝 인덱스가 같거나 크면 계속 반복
while (left <= right) {
let mid: number = left + Math.floor((right - left) / 2); // 중간 인덱스
// 중간값이 찾고자 하는 값과 같으면 중간 인덱스 반환
if (nums[mid] === target) {
return mid;
}
// 중간값이 찾고자 하는 값보다 작으면 왼쪽 영역으로 이동
else if (nums[mid] < target) {
left = mid + 1;
}
// 중간값이 찾고자 하는 값보다 크면 오른쪽 영역으로 이동
else if (nums[mid] > target) {
right = mid - 1;
}
}
// 찾는 값이 없으면 -1 반환
return -1;
}
두 수의 합
nums에서 두 수를 합하여 target를 만드는 조합을 찾는 알고리즘을 무차별 탐색하면 O(n^2)의 시간복잡도, O(1)의 공간 복잡도를 갖는다.
Hash Map을 이용하면 O(n)의 시간복잡도를 갖지만, O(n)의 공간복잡도를 갖게 된다.
투 포인터를 이용하면 O(n)의 시간복잡도와 O(1)의 공간복잡도로 효율적인 풀이가 가능하다.
function twoSum(nums: number[], target: number): number[] {
// 배열의 첫 번째 요소와 마지막 요소를 가리키는 포인터 변수를 초기화합니다.
let left: number = 0;
let right: number = nums.length - 1;
// 포인터가 서로 만날 때까지 반복합니다.
while (left < right) {
// 현재 포인터가 가리키는 두 숫자를 더하여 합을 계산합니다.
let sum: number = nums[left] + nums[right];
// 합이 목표 값과 같으면 결과 배열을 반환합니다.
if (sum === target) {
return [left, right];
} else if (sum < target) {
// 합이 목표 값보다 작으면 합을 크게 만들기 위해 왼쪽 포인터를 이동합니다.
left++; // Make sum bigger
} else if (sum > target) {
// 합이 목표 값보다 크면 합을 작게 만들기 위해 오른쪽 포인터를 이동합니다.
right--; // Make sum smaller
}
}
// 만족하는 두 숫자 쌍이 없으면 [-1, -1]을 반환합니다.
return [-1, -1];
}
배열 뒤집기
자바스크립트에서 배열을 뒤집는 함수도 제공하고 스왑도 제공하지만,
그래도 temp 변수를 이용해 간단히 구현해보자
function reverseArray(nums: number[]): void {
let left: number = 0;
let right: number = nums.length - 1;
while (left < right) {
// Swap nums[left] and nums[right]
let temp: number = nums[left];
nums[left] = nums[right];
nums[right] = temp;
// Move the pointers inward
left++;
right--;
}
}
슬라이딩 윈도우
배열이나 문자열에서 두 개의 포인터를 이용해 슬라이싱 해가면서 풀이한다.
아래는 간단한 Maximum Subarray 문제이다.
가령 배열이 [-2, 1, -3, 4, -1, 2, 1, -5, 4]인 경우,
무차별 탐색을 하면 아래와 같이 전체 경우들이 나온다.
[-2] = -2
[-2, 1] = -1
[-2, 1, -3] = -4
[-2, 1, -3, 4] = 0
[-2, 1, -3, 4, -1] = 3
[-2, 1, -3, 4, -1, 2] = 5
[-2, 1, -3, 4, -1, 2, 1] = 6
[-2, 1, -3, 4, -1, 2, 1, -5] = 1
[-2, 1, -3, 4, -1, 2, 1, -5, 4] = 5
[1] = 1
[1, -3] = -2
[1, -3, 4] = 2
...
O(n^2)이다.
아래는 투 포인터를 이용한 구현이다
function maxSubArray(nums: number[]): number {
let maxSum = -Infinity; // 최대 부분 배열의 합을 저장할 변수 초기값 설정
let windowSum = 0; // 현재 부분 배열의 합을 저장할 변수 초기값 설정
let left = 0; // 현재 부분 배열의 왼쪽 끝 인덱스
for (let right = 0; right < nums.length; right++) {
windowSum += nums[right]; // 현재 부분 배열의 합에 nums[right] 추가
while (windowSum < nums[right]) { // 현재 부분 배열의 합이 nums[right]보다 작을 때
windowSum -= nums[left]; // 현재 부분 배열의 합에서 nums[left]를 뺌
left++; // 부분 배열의 왼쪽 끝 인덱스를 오른쪽으로 이동
}
maxSum = Math.max(maxSum, windowSum); // 최대 부분 배열의 합 갱신
}
return maxSum;
}
경우의 수는 아래와 같이 나온다
1
4
3
6
5
7
8
3
시간복잡도는 O(n)이다.