동적 계획법의 프레임은
- '상태'와 '선택' 찾기
- 'DP 배열'과 'DP 함수'의 정의를 명확히 하기
3' 상태 간의 관계 찾기
로 요약할 수 있다.
동적 계획법의 속성
동적 계획법의 두 가지 속성을 가진다. 참조
- Overlapping Subproblems - 하위 문제의 존재 : DP는 각 부분문제를 해결하여 상위 문제를 해결할 수 있다. 부분 문제의 값이 저장되는 곳이 DP 테이블, 혹은 메모이다.
- Optimal Substructure - 최적 부분 해 : 각 부분 문제의 최적해들을 선택하면 상위 문제의 최적해가 되는 속성을 의미한다.
타 알고리즘과의 관계
하위 문제만 존재하면 - 백트래킹
최적 부분해 + Greedy Choice Property(탐욕적 선택 속성) - 그리디 알고리즘
(Greedy 알고리즘은 현실에서는 최적해를 보장하지 않는 경우가 있지만 코딩 테스트에서는 최적해를 보장한다.)
기본 예제
예제1. 최장 증가 부분수열 (LIS)
리트코드 300 - 최장 증가 부분 수열
문제 : nums 배열을 입력받아, 증가하는 최장 부분 수열의 길이를 출력하라.
입출력
Input: nums = [10,9,2,5,3,7,101,18]
Output: 4
해설 : [2,3,7,101]가 최장 증가 부분 수열이다.
제약조건
1 <= nums.length <= 2500
-104 <= nums[i] <= 104
DP 풀이
- DP배열의 정의
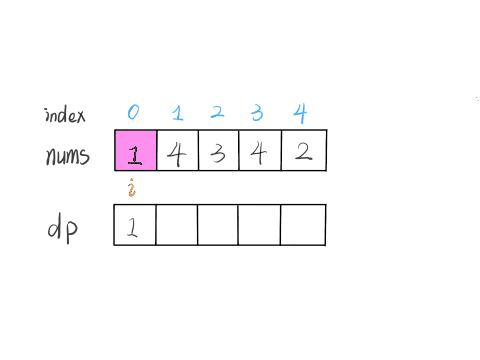
dp[i] : nums[i]로 끝나는 최장 증가 수열의 길이
즉 dp테이블은 인덱스 i까지 순차적으로 정복해가는 바텀업의 풀이 방식이 된다.
모든 배열은 1로 초기화 된다. (자기 자신이 포함되기 때문이다.) - DP함수
dp[i]를 구하기 위해 dp배열의 첫번째 요소부터 순회한다. 해당 요소dp[j]가dp[i]보다 크다면, 해당 요소까지의 수열 + 현재의 인덱스, 즉dp[j]+1이 dp배열의 값이 될 수 있다.
nums.forEach((num, index)=>{
if(nums[i] > num) {
dp[i] = Math.max(dp[i], dp[index]+1);
}
결과
function lengthOfLIS(nums: number[]): number {
// 정의: dp[i]는 nums[i]로 끝나는 가장 긴 증가하는 부분 수열의 길이를 나타냅니다.
const dp: number[] = new Array(nums.length).fill(1);
// base case: dp 배열은 모두 1로 초기화합니다.
for (let i = 0; i < nums.length; i++) {
for (let j = 0; j < i; j++) {
if (nums[i] > nums[j]) {
dp[i] = Math.max(dp[i], dp[j] + 1);
}
}
}
let res = 0;
for (let i = 0; i < dp.length; i++) {
res = Math.max(res, dp[i]);
}
return res;
}
시간 복잡도는 O(N^2)이다.
이진탐색 풀이
이진 탐색으로 풀이하면 O(n log n)이다. 하지만 실제로 이러한 풀이를 떠올리기는 쉽지 않다.
DP 문제들은 수학적 귀납법을 푸는 알고리즘이며, 이에 따라 이와 같은 이진탐색도 가능하다는 사례이다.
스파이더 카드 놀이 (인내 게임)을 떠올려보자
- 카드덱의 왼쪽부터 탐색한다.
- 배치가 가능한 더미가 없으면 새 더미에 둔다.
- 배치가 가능한 더미가 있으면 해당 더미에 쌓는다.
(즉 여러개의 더미에 배치할 수 있으면 왼쪽부터 쌓인다.)

위 과정의 3번 조건에 의해, 더미들의 마지막 카드들을 확인하면 2, 4, 7, 8, Q로 부분증가수열로 정렬되며, 해당 부분증가수열의 길이가 최장부분증가수열 3, 5, 7, 8, Q의 길이와 같다.
위의 풀이를 이진탐색으로 하면 아래와 같다.

function lengthOfLIS(nums: number[]): number {
const top: number[] = new Array(nums.length);
// 카드 더미 수를 0으로 초기화
let piles = 0;
for (let i = 0; i < nums.length; i++) {
// 처리할 포커 카드
const poker = nums[i];
/***** 왼쪽 경계를 찾는 이분 탐색 *****/
let left = 0,
right = piles;
while (left < right) {
const mid = Math.floor((left + right) / 2);
if (top[mid] > poker) {
right = mid;
} else if (top[mid] < poker) {
left = mid + 1;
} else {
right = mid;
}
}
/*********************************/
// 적절한 카드 더미를 찾지 못했으면 새로운 더미를 만듦
if (left == piles) piles++;
// 이 카드를 카드 더미 맨 위에 놓음
top[left] = poker;
}
// 카드 더미 수가 LIS의 길이
return piles;
}
예제2. 2차원 증가 부분 수열 (마트료시카 봉투 중첩)
봉투안에 봉투를 넣을 수 있다.
이때 가로나 세로가 크거나 같은 봉투는 넣을 수 없다.
Input: envelopes = [[5,4],[6,4],[6,7],[2,3]]
Output: 3
Explanation: The maximum number of envelopes you can Russian doll is 3 ([2,3] => [5,4] => [6,7]).
해당 문제를 해결하는 방법은 간단한데,
높이 혹은 넓이 중 하나로 정렬을 하는 것이다.
이렇게하면 나머지 하나의 배열에 대한 LIS를 구하는 문제로 치환된다.
이와 같이 2차원 배열 문제는 정렬을 통해 쉬운 문제로 치환할 수 있다.

리트코드 354의 시간 조건이 까다로워 일부 O(n^2)의 LIS를 시행하면 테스트케이스를 실패할 수 있다.
이에 따라 이진탐색을 이용하여 O(n log n)으로 LIS를 찾도록 코드를 짜야 한다.
아래는 ChatGPT가 짜준 코드이다.
/**
* 문제: https://leetcode.com/problems/russian-doll-envelopes/
* 시간 복잡도: O(NlogN)
* 공간 복잡도: O(N)
*/
function maxEnvelopes(envelopes: number[][]): number {
const n = envelopes.length;
// envelopes 배열을 너비를 기준으로 오름차순으로 정렬합니다.
envelopes.sort((a, b) => a[0] - b[0]);
// LIS 배열 초기화
const lis: number[] = new Array(n).fill(0);
let len = 0;
// envelopes 배열에서 높이만 추출하여 LIS를 계산합니다.
for (let i = 0; i < n; i++) {
const height = envelopes[i][1];
let index = binarySearch(lis, 0, len, height);
if (index < 0) {
index = -(index + 1);
}
lis[index] = height;
if (index === len) {
len++;
}
}
return len;
}
/**
* 이진 탐색을 수행합니다.
* @param nums 탐색할 배열
* @param left 탐색 범위의 시작 인덱스
* @param right 탐색 범위의 끝 인덱스
* @param target 찾을 값
* @returns 찾은 값의 인덱스 또는 찾지 못했을 경우 -(삽입 위치 + 1)을 반환합니다.
*/
function binarySearch(nums: number[], left: number, right: number, target: number): number {
while (left < right) {
const mid = Math.floor((left + right) / 2);
if (nums[mid] < target) {
left = mid + 1;
} else {
right = mid;
}
}
return left < nums.length && nums[left] === target ? left : -(left + 1);
}
예제3. 최대 부분 배열
배열의 일부를 슬라이싱하여 최대의 합을 갖는 부분 배열을 찾는 문제이다.
Input: nums = [-2,1,-3,4,-1,2,1,-5,4]
Output: 6
Explanation: [4,-1,2,1]
문제 분석
0. 완전 탐색이 가능하나, O(n^2)의 시간 복잡도를 가진다.
- 슬라이딩 윈도우로 O(n)으로 풀 수 있을 것으로 보일 수 있으나, 음수로 인해 슬라이딩 윈도우의 확장/축소 시점이 명확하지 않다.
- 이에 따라 각 부분 배열의 결과를 저장할 DP 테이블이 필요해진다.
- DP 배열을 어떻게 정의해야 하는가? 만일 DP배열을
DP[i]는nums.slice(0,i+1)의 최대 부분 배열 합일 것이다. - 하지만
DP[i]를 이용해DP[i+1]을 추론하는 것은 불가능하다.nums.slice(0,i+1)의 최대 부분배열의 합과nums.slice(0,i+\2)의 최대 부분배열 합이 서로 인접하지 않은 서로 다른 최대 부분배열을 가질 수 있기 때문. 따라서 해당 문제는 앞에서부터 부분적으로 문제를 해결해가는, 소위 '수학적 귀납법' 형태의 문제가 아니다.
그렇다면 DP[i-1]의 값으로 DP[i]는 어떻게 추론하는가?
두 가지의 선택을 생각할 수 있다.
DP[i-1]까지의 부분배열에nums[i]를 병합한다.nums[i]를 시작 인덱스로 하는 새로운 부분배열을 만든다.
위의 DP 방정식을 작동시키면
새로운 부분 배열이 만들어져서 확장되어 가거나, 새로운 부분 배열을 만들지 못하고 별도의 요소로 떨어져나와 배열을 끊는 역할을 한다.
즉 위 두 가지의 선택으로 인해
- 배열을 만들거나
- 배열을 끊고 새로 시작하거나
의 상태 변화가 일어난다.
function maxSubArray(nums: number[]): number {
const n = nums.length;
if (n === 0) return 0;
// 정의: dp[i]는 nums[i]를 끝으로 하는 "최대 부분 배열의 합"을 기록합니다.
const dp: number[] = new Array(n);
// base case
// 첫 번째 요소 이전에는 부분 배열이 없습니다.
dp[0] = nums[0];
// 상태 전이 방정식
for (let i = 1; i < n; i++) {
dp[i] = Math.max(nums[i], nums[i] + dp[i - 1]);
}
// nums의 최대 부분 배열을 구합니다.
let res = Number.MIN_SAFE_INTEGER;
for (let i = 0; i < n; i++) {
res = Math.max(res, dp[i]);
}
return res;
}
그리고 보면 알겠지만 '기존 배열의 합계' 혹은 '새로운 배열의 시작점', 두 개의 값만 가져가면 된다.
따라서 O(n)의 공간 복잡도를 O(1)로 상태압축을 하면 된다.
function maxSubArray(nums: number[]): number {
const n: number = nums.length;
if (n === 0) return 0;
// base case
let dp_0: number = nums[0]; // 초기값은 첫 번째 원소
let dp_1: number = 0,
let res: number = dp_0;
for (let i = 1; i < n; i++) {
// dp[i] = max(nums[i], nums[i] + dp[i-1])
dp_1 = Math.max(nums[i], nums[i] + dp_0); // 현재 원소와 이전 최대 부분합과의 합 중 더 큰 값으로 갱신
dp_0 = dp_1; // 다음 계산을 위해 현재 값을 이전 값으로 대체
// 최대 결과 계산
res = Math.max(res, dp_1);
}
return res;
}
결론
DP문제는
- Overlapping Subproblems - 하위 문제
- Optimal Substructure - 최적 부분해
를 가진다.
그리고 DP문제는
- 수학적 점화식을 이용해 다음 상태가 결정된다.
- 수학적 점화식이 아니더라도, '상태 전이' 방정식으로 다음 상태가 결정된다.
DP에 대한 논의
최적 하위 구조는?
하위 문제로 상위 문제의 답을 추론할 수 있으면 최적 하위구조다.
만일 10개의 반에서 전교 1등의 성적을 출력한다고 해보자.
각 반의 1등을 구해 10명을 추린다.
10명 중 성적이 가장 높은 1명이 전교 1등이다.
한편 전교 1등과 전교 꼴등의 점수차이를 구한다고 해보자.
이 경우 각 반 1등과 각 반 꼴등의 점수차이를 계산하는 것은 의미가 없으며, DP가 아닌 무차별 탐색 문제로 진행해야 한다.
위 두 문제를 통해 알 수 있는 것은 '하위 문제'와 '상위 문제'는 상호독립적이어야 한다는 것이다. 두번째 예시는 어떤 반 1등과 어떤 반 꼴등의 점수차이를 의미하며, 서로 다른 반이 상호 의존적인 문제이기에 각 반의 문제는 상위 문제를 해결할 수 없다.
때문에 트리 문제가 대표적인 DP 유형 문제인 이유도 자식 트리들의 결과가 부모 트리에 그대로 반영되기 때문이다.
순회 방향은?
순방향, 역방향 등 다양한 방식을 고려할 수 있고,
또 경우에 따라서는 두 방향 모두에서 풀이가 가능할 수 있다.
중요한 것은 어느 방향으로 탐색하는지가 아니라
'정답이 어느 방향에서 오는지' 이다.
정답을 찾을수만 있다면 대각선이든 직선이든, 순방향이든 역방향이든 상관없다. 정답이 어느 방향에서부터 정답을 받을 수 있는지를 확인하라. 대부분의 경우 시간 복잡도는 동일하다.
최장공통부분순열 (Longest Common Subsequence)
1143. Longest Common Subsequence
str1="abcde", str2="aceb"가 있을 때,
최장 공통 부분순열은 a, c, e이다.
대표적인 2차원 동적계획법 문제이다.
부분 순열 문제는 완전 탐색이 쉽지 않아 가지치기가 들어가고, 그러다보니 대부분의 부분 순열은 동적계획법으로 풀이된다.

- DP배열 : 각 문자열을 배열로 하여 가로축, 세로축으로 한다. 즉 두 문자열을 비교하는 문제는 2차원 배열이 된다.
dp[i][j]는 해당 문자열까지 탐색하여 얻은 최장공통부분의 길이가 되고,dp[s1.length - 1][s2.length - 2]의 값이 문자열 전체를 탐색하여 얻는 최장공통부분이므로 답이 된다. - base case : '최장'을 찾으므로 모든 문자열을 0으로 초기화한다.
- 상태전이방정식 :
s1[i] === s2[j]이면 "최장공통 부분순열"이 1 증가할 것이다. 그리고 "최장공통 부분순열"은 현재까지 탐색한s1[0...i-1]과s2[0...j-1]의 결과를 의미하며, 따라서dp[i][j] = dp[i-1][j-1]+1이 된다.- 문제는
s1[i] !== s2[j]인 경우이다. 둘 중 하나는 LCS에 포함되지 않는 문자이다. 이 경우 아래와 같이 둘 중 하나씩 제외한 두 단계 중 더 긴 값이 답이 된다.
db[i][j] = max(dp[i-1][j], dp[i][j-1]) - 위에서 예외가 하나 더 있다. 둘 다, LCS에 포함되지 않는 경우이다. 이 경우에는 둘 다 한 단계씩 제외하여야 한다. 따라서 상태전이 방정식이 아래와 같이 최종적으로 수정된다.
db[i][j] = max(dp[i-1][j], dp[i][j-1], dp[i-1][j-1])
- DP 테이블: 동적 계획법(Dynamic Programming)에서 부분 문제(subproblem)의 답을 저장하고 재사용하기 위해 만든 2차원 배열
- 기본 사례(base case): 동적 계획법에서 재귀 호출을 멈추기 위한 최소 문제의 해답
- 상태 전이(state transition): 동적 계획법에서 부분 문제의 해답을 구하기 위해 이전 단계의 결과를 이용하여 다음 단계의 결과를 계산하는 과정
- lcs(최장 공통 부분 문자열): 두 문자열에서 공통으로 나타나는 가장 긴 부분 문자열
function longestCommonSubsequence(str1: string, str2: string): number {
const m: number = str1.length;
const n: number = str2.length;
// DP 테이블 및 기본 사례(base case) 구성
const dp: number[][] = Array.from(Array(m + 1), () => new Array(n + 1).fill(0));
// 상태 전이(state transition) 진행
for (let i = 1; i <= m; i++) {
for (let j = 1; j <= n; j++) {
if (str1[i - 1] === str2[j - 1]) {
// lcs(최장 공통 부분 문자열)의 문자��� 찾음
dp[i][j] = 1 + dp[i-1][j-1];
} else {
dp[i][j] = Math.max(dp[i-1][j], dp[i][j-1], dp[i-1][j-1]);
}
}
}
return dp[m][n];
}
(참고로 위 풀이는 상태 압축이 가능하다. )
앞서 DP는 정답을 어디서부터 찾아가느냐보다 정답이 어디에서부터 추출되는지가 중요하다고 하였다.

DP[i][j]는 대각선 왼쪽 위, 위, 왼쪽으로부터 정답이 추출되며, 이에 따라 위에서 아래, 혹은 왼쪽에서 오른쪽으로 탐색한다면 어느 방향이든 정답을 얻을 수 있다.
편집 거리 (Levenshtein 거리 알고리즘)
문자열 하나를 삽입, 삭제, 변경(replace)하는 조작이 가능하다.
s1이 s2가 되도록 하는 최소 조작수를 구하라.
Input: word1 = "intention", word2 = "execution"
Output: 5
Explanation:
intention -> inention (remove 't')
inention -> enention (replace 'i' with 'e')
enention -> exention (replace 'n' with 'x')
exention -> exection (replace 'n' with 'c')
exection -> execution (insert 'u')
무차별 해법으로는 투 포인터로 해당 값들을 비교하며 진행하면 된다.
def minDistance(s1, s2) -> int:
def recur(i, j):
# base case
if i == -1: return j + 1
if j == -1: return i + 1
if s1[i] == s2[j]:
return recur(i - 1, j - 1) # skip
else:
return min(
recur(i, j - 1) + 1, # insert
recur(i - 1, j) + 1, # delete
recur(i - 1, j - 1) + 1 # replace
)
# i,j initialize to the last index
return recur(len(s1) - 1, len(s2) - 1)
하지만 LCS와 마찬가지로 2차원 DP로 풀이할 수 있다.
문제 해결을 위해 첫번째로 떠올려야 할 것은 '최장 공통' 문제의 해법이다. 이번엔 '최소' 편집 거리를 구한다. 따라서 DP로 2차원 배열을 탐색하면서 최소를 구하면 된다.
s1[i] === s2[j]이면 아무 것도 하지 않고 진행한다. 따라서dp[i][j] === dp[i-1][j-1]과 같다.- 만일
s1[i] !== s2[j]일 때
- 만일 s1에 새로운 문자를 삽입한다고 가정해보자.
s1[i]가 한 칸 뒤로 밀린다. (이는s2[j]를 한 칸 앞으로 미는 것과 같은 의미이다.)
dp(i, i - 1) + 1 - 만일 s1에서 기존 문자를 삭제한다고 가정해보자.
s1[i]를 한 칸 앞으로 밀게 된다.
dp(i - 1, j) + 1 - 문자를 변경하는 경우에는 기존 포인터를 그대로 둔 채 연산이 증가하는 것과 같다.
dp(i - 1, j - 1) + 1
이를 DP테이블을 이용하여 먼저 탐색 후, 없는 경우에만 DP를 호출하면 된다.
function minDistance(s1: string, s2: string): number {
const memo: Map<string, number> = new Map(); // memo
function dp(i: number, j: number): number {
const key = `${i},${j}`;
if (memo.has(key)) {
return memo.get(key)!;
}
...
if (s1[i] === s2[j]) {
memo.set(key, ...);
} else {
memo.set(key, ...);
}
return memo.get(key)!;
}
return dp(s1.length - 1, s2.length - 1);
}
function minDistance(s1: string, s2: string): number {
const memo: { [key: string]: number } = {}; // memo
function dp(i: number, j: number): number {
const key = `${i},${j}`;
if (key in memo) {
return memo[key];
}
if (i === -1) {
memo[key] = j + 1;
} else if (j === -1) {
memo[key] = i + 1;
} else if (s1[i] === s2[j]) {
memo[key] = dp(i - 1, j - 1);
} else {
memo[key] = Math.min(
dp(i - 1, j) + 1, // 삭제
dp(i, j - 1) + 1, // 삽입
dp(i - 1, j - 1) + 1 // 교체
);
}
return memo[key];
}
return dp(s1.length - 1, s2.length - 1);
}

재귀 함수를 이용하면 아래에서 위로 올라가는 바텀업 방식이 된다.
두 알고리즘의 차이는 없다.
function minDistance(s1: string, s2: string): number {
const m = s1.length, n = s2.length;
// 정의: s1[0..i]와 s2[0..j]의 최소 편집 거리는 dp[i+1][j+1]이다.
const dp: number[][] = new Array(m + 1).fill(null).map(() => new Array(n + 1).fill(0));
// 초기값
for (let i = 1; i <= m; i++)
dp[i][0] = i;
for (let j = 1; j <= n; j++)
dp[0][j] = j;
// bottom-up 방식으로 해결
for (let i = 1; i <= m; i++) {
for (let j = 1; j <= n; j++) {
if (s1.charAt(i - 1) === s2.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1];
} else {
dp[i][j] = min(
dp[i - 1][j] + 1,
dp[i][j - 1] + 1,
dp[i - 1][j - 1] + 1
);
}
}
}
// s1과 s2의 전체 최소 편집 거리를 저장함
return dp[m][n];
}
function min(a: number, b: number, c: number): number {
return Math.min(a, Math.min(b, c));
}
최장 회문 부분 수열 (가장 긴 팰린드롬)
https://leetcode.com/problems/longest-palindromic-substring/
dp배열의 정의
1차원과 2차원 모두 가능하다.
1차원 DP 배열 : array[i]로 끝나는 최장 증가 부분 수열의 길이는 dp[i]가 된다. 귀납법이 가능하기 때문에 이와 같은 1차원 배열을 사용할 수 있다.
for (int i = 1; i < n; i++) {
for (int j = 0; i < i; i++) {
dp[i] = Math.max(dp[i], dp[j] +...)
}
}
2차원 DP 배열 :
배열이 두 개인 경우, 배열1[...i]과 배열2[...j]의 사이의 요건을 충족한 부분 수열(가령 공통 부분 수열)의 값이다.
배열이 하나인 경우, 문자i부터 문자j까지의 요건을 충족한 부분수열(가령 최장 회문 수열)의 값이다.
풀이
부분 문자열은 연속되지 않은 문자열을 의미한다.
최장 회문 부분 수열이란,
문자열 s = aecda로 주어질 때, aca가 최장 회문 부분 수열이다.
- 투 포인터로 회문 찾기
위에서 영감을 얻으면, left, right만 같아도 최장 회문 부분수열이다. abcdefga도 a, a를 같은 부분 수열이다.
투 포인터를 벌려가면서, 같다면 문자열에 추가하고, 길이가 최대하면 해당 문자열을 정답에 저장해두는 방식으로 진행하면 된다.
function palindrome(s, l, r) {
// outOfIndex 에러를 방지합니다.
while (l >= 0 && r < s.length
&& s[l] == s[r]) {
// 양쪽 방향으로 스캔합니다.
l--; r++;
}
// s[l]과 s[r]을 중심으로 하는 회문을 반환합니다.
return s.substring(l + 1, r);
}
function longestPalindrome(s) {
let res = "";
for (let i = 0; i < s.length; i++) {
// s[i]을 중심으로 하는 회문을 찾습니다.
let s1 = palindrome(s, i, i);
// s[i]과 s[i+1]을 중심으로 하는 회문을 찾습니다.
let s2 = palindrome(s, i, i + 1);
// res = longest(res, s1, s2)
res = res.length > s1.length ? res : s1;
res = res.length > s2.length ? res : s2;
}
return res;
}
공간복잡도는 O(1)이지만, 시간 복잡도는 O(n^2)이다.
- DP 배열
투 포인터를 사용한 알고리즘이 정석이지만,
DP를 통한 풀이로 접근해보자.
만일 ij의 부분 수열의 길이를 알 때에, i+1j+1의 부분 수열의 길이를 알 수 있을까? 알 수 있다. i+1과 j+1이 같다면 부분 수열의 길이가 2 증가한다.
만일 i+1과 j+1이 같지 않다면?
[i+1][j], [i][j+1] 두 문자열을 비교해서 더 긴 문자열이 i+1~j+1의 최장 회문 공통부분수열이 된다.
DP배열 : DP[i][j]는 문자열 [i]~[j]까지 찾은 조건을 충족하는 부분수열을 의미한다.
base case : 모든 문자는 그 스스로가 길이가 1인 회문이다. 따라서 dp배열을 1로 초기화 한다.
상태 전이 방정식 :
if(s[i] === s[j]) {
dp[i][j] = dp[i + 1][j - 1] + 2;
} else {
dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);
}
이 상태전이 방정식을 이용하여 순회를 시작하면 된다.
그렇다면 어느 방향으로 순회해야 할까?

dp[0][n-1]이 우리가 구하고자 하는 최종 위치가 된다.
dp[0][n-1]을 구하기 위해서는
dp[0][n-2], dp[1][n-1], dp[1][n-2]을 알아야 한다.
이렇게 순차적으로 채워가기 위해서는
base case부터 대각선 방향(혹은 역방향)으로 순차적으로 채워나가면 된다.
아래는 대각선의 역방향으로 순회하는 코드이다.
function longestPalindromeSubsequence(s) {
const n = s.length;
const dp = Array.from({ length: n }, () => Array(n).fill(0));
// dp[i][i]는 길이가 1인 팰린드롬 부분문자열이므로 모두 1로 초기화합니다.
for (let i = 0; i < n; i++) {
dp[i][i] = 1;
}
// 길이가 2인 팰린드롬 부분문자열부터 시작해서 dp 테이블을 채웁니다.
for (let i = n - 2; i >= 0; i--) {
for (let j = i + 1; j < n; j++) {
if (s[i] == s[j]) {
dp[i][j] = dp[i + 1][j - 1] + 2; // 양 끝 문자가 같으면 dp[i+1][j-1]에 저장된 값에 2를 더합니다.
} else {
dp[i][j] = Math.max(dp[i + 1][j], dp[i][j - 1]); // 양 끝 문자가 다르면 dp[i+1][j]와 dp[i][j-1] 중 큰 값을 선택합니다.
}
}
}
return dp[0][n - 1]; // 전체 문자열에서 가장 긴 팰린드롬 부분문자열의 길이를 반환합니다.
}
상태 압축
상태압축을 하려면 각 위치마다 팰린드롬 부분문자열의 길이를 저장할 필요가 있습니다. 이를 위해 1차원 dp 배열을 사용하며, dp[i]는 i부터 문자열의 끝까지의 최대 팰린드롬 부분문자열의 길이를 저장합니다.
초기값은 dp[i] = 1로 설정하고, 길이가 2인 부분문자열부터 시작해서 dp 배열을 채워나갑니다. 각 위치 i에서 시작하는 길이 j인 부분문자열이 팰린드롬인지 아닌지를 판별하는데, 이때 i부터 j까지의 문자열이 팰린드롬인지 아닌지는 dp[i+1]부터 dp[j-1]까지의 값으로 판별할 수 있습니다. 따라서 j부터 i까지 순차적으로 탐색하며 dp[i]값을 갱신해나갑니다.
아래는 상태압축을 적용한 코드입니다.
function longestPalindromeSubsequence(s) {
const n = s.length;
const dp = Array(n).fill(1); // 초기값 설정
let prev; // 이전 상태 값을 저장할 변수
for (let i = n - 2; i >= 0; i--) {
prev = 0; // 이전 상태 값 초기화
for (let j = i + 1; j < n; j++) {
const temp = dp[j]; // 이전 상태 값을 저장
if (s[i] == s[j]) {
dp[j] = prev + 2; // dp[j] 갱신
} else {
dp[j] = Math.max(dp[j], dp[j - 1]); // dp[j] 갱신
}
prev = temp; // 이전 상태 값 갱신
}
}
return dp[n - 1]; // 최종 상태 값 반환
}
프로그래머스
12907. 거스름돈
거슬러 줘야 하는 금액 n과 Finn이 현재 보유하고 있는 돈의 종류 money가 매개변수로 주어질 때, Finn이 n 원을 거슬러 줄 방법의 수를 return 하도록 solution 함수를 완성해 주세요.
문제 해설 : 다른 문제와 다르게 전체 경우의 수를 반환하는 문제이다.
풀이
1원, 2원이 있을 때
3원을 만드는 경우의 수를 따져보자.
[1, 1, 1], [2, 1], [1, 2]의 경우의 수가 있을 수 있다.
문제의 테스트 케이스의 답은 2이다. 즉 [1, 1, 1]과 [1, 2]를 같은 것으로 친다. 즉 조합을 구하는 문제이다.
DP의 '선택'을 잘 골라야 한다.
만일 선택을 'target 만들고자 하는 금액'으로 두면 순열이 구해져버린다.
따라서 선택을 'coin 돈의 단위'으로 두어 하나의 돈의 단위가 한 번만 선택되도록 할 수 있다.
(DP와 조합 참조 파스칼 삼각형)
따라서 아래와 같이 DP를 짤 수 있다.
- DP 테이블 : DP[target]은 target을 만들 수 있는 조합의 수이다.
- Base Case : target이 0일 때, 이 값을 1로 둔다.
- 선택 : 동전 Coin을 작은 순으로 고른다.
- 상태전이 : DP를 작은 순으로 순회하며, 동전 Coin을 이용하여 만드는 경우의 수를 더해준다.
가령 동전이 1원일 때,
DP[1]은 1
DP[2]는 1 - [1, 1]
DP[3]은 1 - [1, 1, 1] 이다.
동전이 2원일 때,
DP[1]은 0,
DP[2]는 1 - [2]
DP[3]은 1 - [2, 1] 이다.
결과적으로 DP 테이블은 [1, 1, 2, 2]가 된다.
상태전이 방정식이 DP[target]을 갈아끼우는 것이 아닌 DP[target]에 특정 값을 더해가는 특이한 문제라 할 수 있다. (물론 '최소한의 동전으로 target을 거슬러주는 경우'로 문제가 출제된다면, DP[target]을 Math.min을 이용하여 갈아끼워주어야 한다.)
function solution(n, money) {
var answer = 0;
//DP테이블을 앞에서 부터 채우기 위해 동전을 작은 단위부터 큰 단위 순으로 정렬한다.
money.sort((a,b)=>a-b)
//DP 테이블 : N원을 만들 수 있는 경우의 수
const dp = Array(n+1).fill(0)
//base case : 0원을 만들 수 있는 경우의 수는 1개
dp[0] = 1
//DP함수 :
// 선택 - 동전을 선택한다
// 실행 - 해당 동전을 이용해서 target을 만드는 경우의 수를 추가한다
// 예외 - 해당 동전과 같은 값을 만드는 경우의 수가 여러 개라면 그것들도 포함한ㄷ.
money.forEach(coin=>{
for(let target=coin; target <= n; target++) {
dp[target] += dp[target - coin]
}
})
answer = dp[n]
return answer
}
수학적으로는 dp[target]은
조합의 수인 nCr을 이용하여 나타낼 수 있다.
여기서 n은 주어진 동전의 개수(target보다 작은 동전의 갯수)이고, r은 target원을 만들 때 선택된 동전의 개수이다. 따라서 dp[target]은 n개의 동전 중에서 r개를 선택하는 조합의 수를 모두 더한 것과 같다.
즉, dp[N] = nCr(1, r) + nCr(2, r) + ... + nCr(n, r) 이라고 표현할 수 있다.