정의
트리 자료구조란 '하나의 부모'와 '하나 이상의 자식'으로 구성된 그래프를 의미한다. 데이터의 계층을 나타내는데에 사용된다.
트리 구조의 판별
트리는 다음의 특징을 갖는다.
- 정점들이 연결되어 있다.
- 연결된 그래프들 간에 cycle이 없다.
- cycle이 없다는 것은 n개의 노드가 n-1개의 간선으로 연결되어 있다는 것을 의미한다.
트리의 판별은 dfs를 통해 손쉽게 할 수 있다. 주어진 간선 배열을 순회하며 방문했을 때,
- 방문하지 않은 노드가 있다면, 해당 노드는 트리에 연결되지 않은 노드이다.
- 방문한 노드를 또 방문하게 된다면, 해당 노드를 포함한 cycle이 있다는 것이므로 해당 그래프는 트리가 아니며, 해당 노드가 연결된 간선 중 하나 이상을 제거하여야 트리가 된다.
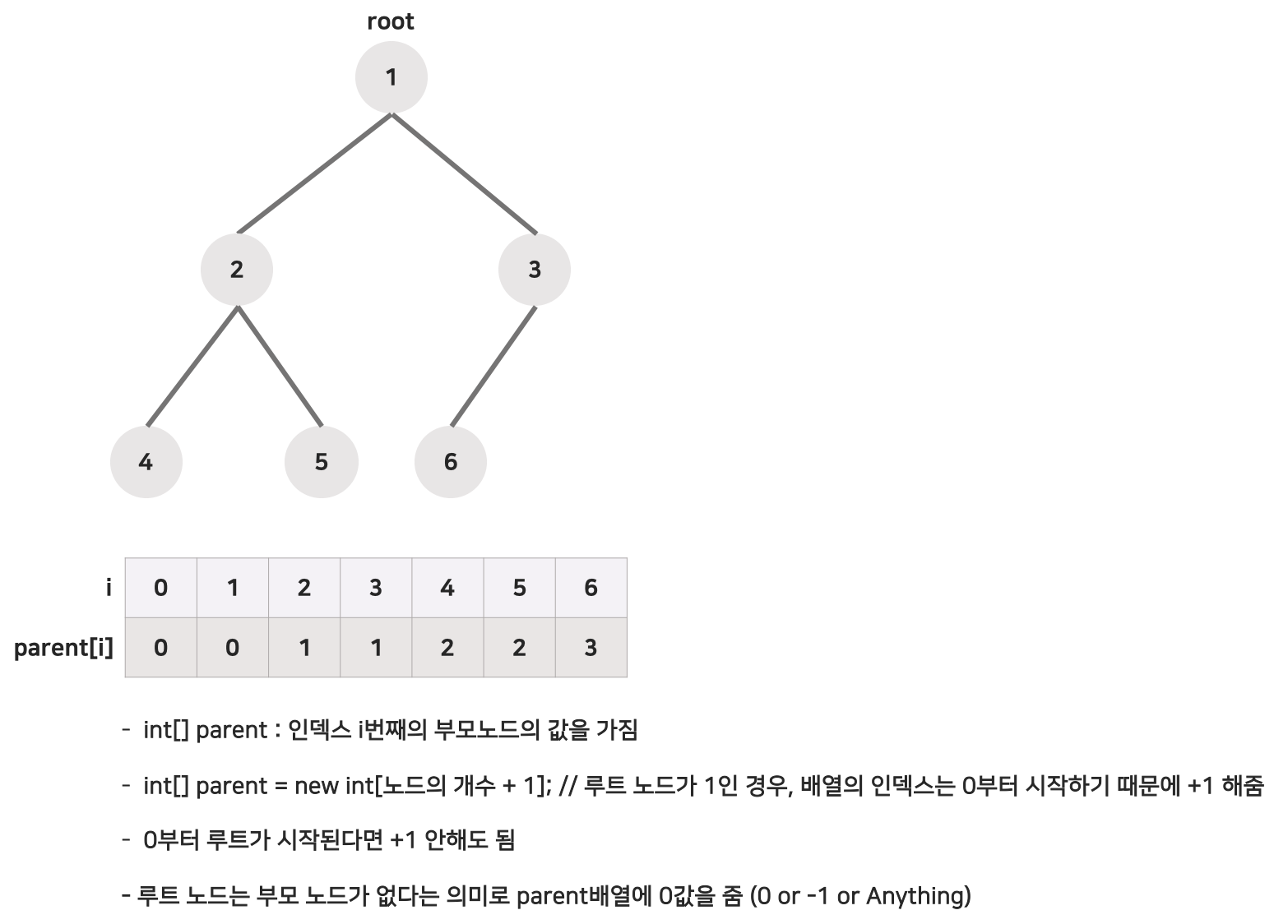
임의의 두 노드가 같은 트리에 있는지를 판별하는 로직은 다음과 같다.
- 트리 구조는 '하나의 부모'를 갖는다.
- '하나의 부모'를 거슬러 올라가면 하나의 루트 노드를 발견하게 된다.
- '루트 노드'가 같으면 같은 트리에 속한 노드이다.
위 문제는 'Union Find 자료구조'라는 이름으로도 불리며, bfs와 dfs중 bfs로 구현하는 쪽이 더 간결한 코드가 나온다.
간선 그래프가 [ 2-3, 1-2, 4-5 ]로 주어지고, 각각의 노드 1,2,3,4,5가 있다고 가정해보자.
union 연산
각각의 노드를 (나, 부모노드)의 구조로 만든다.
- 초기엔 자기 자신을 부모노드로 갖는다.
[(1, 1), (2, 2), (3, 3), (4, 4), (5, 5)] - 간선 배열을 순회하며 연결된 배열의 부모노드를 한 쪽으로 통일시킨다. 주로 작은 쪽으로 통일시킨다.
2-3 간선[(1, 1), (2, 2), (3, 2), (4, 4), (5, 5)]
1-2 간선[(1, 1), (2, 1), (3, 2), (4, 4), (5, 5)]
4-5 간선[(1, 1), (2, 1), (3, 2), (4, 4), (5, 4)]
union연산이 완료되었다. (2번 노드와 3번 노드의 부모 노드가 하나로 일치하지 않는 모습을 볼 수 있는데, 이러한 문제를 해결하기 위해서는 간선 그래프도 일정한 기준에 맞추어 미리 정렬해두거나, 그래프 순회를 2회 돌리면 된다.)
find 연산
특정 노드을 조회했을 때, 해당 노드의 부모노드를 거슬러가며 '나 === 부모노드'인 간선을 찾으면 해당 노드가 루트노드다.
3의 부모노드를 찾는 경우
3 -> 2 -> 1로 거슬러 올라가며, 1이 루트노드다.
서로소 판별
3과 4를 find했을 때,
find(3) = 1
find(4) = 4
두 노드의 루트노드가 다르다. 이 둘은 서로 다른 트리이며, 이 둘은 '서로소'이다.
이진 트리
이진 트리란 '하나의 부모'가 '최대 두 개의 자식'을 가짐을 의미한다. 한편 왼쪽의 자식
'포화 이진트리'란, 모든 레벨의 모든 부모가 2개의 자식을 가지고 있음을 의미한다.

'완전 이진트리'란, 각 레벨의 왼쪽부터 자식노드를 채워넣는 것을 의미한다.

포화 이진트리(를 비롯한 완전 이진트리)는 균형 이진트리이다.
따라서 레벨(깊이)는 log_2의 n승으로 증가한다.

사진출처
이진 탐색트리란 왼쪽 자식노드는 부모노드보다 작고, 오른쪽 자식노드는 부모보다 크다는 조건 하에 정렬되는 이진트리 이다.
이진트리는 삽입 O(log n), 삭제 O(log n), 정렬 O(n log n)의 시간 복잡도를 갖는다.
힙 자료구조와 우선순위 큐
힙 자료구조는 데이터가 삽입/삭제될 때마다 특정 조건에 맞추어 정렬하는 자료구조를 의미한다. 가령 '최대힙'은 부모노드가 자식노드보다 항상 크다. '최소힙'은 부모노드가 자식노드보다 항상 작다. 새로운 노드가 추가되면, 해당 노드는 부모를 거슬러 올라가며 정렬하며, 삽입의 시간 복잡도는 O(log n)이다. '루트 노드를 삭제'하는 연산의 시간 복잡도 역시 O(log n)의 시간 복잡도를 갖는다.
우선순위 큐는 새로운 값을 shift, unshift할 때마다 정렬을 하는 큐를 의미한다. 따라서 새로운 갑을 추가, 삭제 sort()를 실행하므로 추가, 삭제의 시간복잡도는 sort의 시간복잡도인 O(n log n)이다. 병합 정렬(Merge Sort)과 퀵 정렬(Quick Sort)의 조합으로 구현되어 있기 때문.
반면 우선순위 큐를 힙 자료구조를 이용해 구현하면 추가, 삭제의 시간복잡도가 O(log n)이 되어 매우 효율적이다.
자바스크립트로 구현
class를 이용하여 구현할 수 있지만,
완전 이진트리의 속성을 이용하면 배열로도 가능하다.

사진출처
이처럼 특정 레벨의 첫번째 값은 항상 2^(level-1)이다.
그리고 특정 레벨의 최대 노드 갯수 역시 2^(level-1)이다.
이를 이용하여 길이가 2^maxLevel인 배열을 초기화한 후, 하나씩 값을 채워가면 완전이진트리를 구현할 수 있다.
아래는 자바스크립트로 완전 이진트리를 구현하고, 힙 연산이 추가된 예시이다.
function buildHeap(arr) {
// 배열의 중간 인덱스부터 시작하여 힙 속성을 만족하도록 조정합니다.
for (let i = Math.floor(arr.length / 2); i >= 0; i--) {
heapify(arr, i, arr.length);
}
return arr;
}
function heapify(arr, i, n) {
let largest = i;
const left = 2 * i + 1;
const right = 2 * i + 2;
// 왼쪽 자식이 더 큰 경우
if (left < n && arr[left] > arr[largest]) {
largest = left;
}
// 오른쪽 자식이 더 큰 경우
if (right < n && arr[right] > arr[largest]) {
largest = right;
}
// 부모와 큰 자식을 교환하고, 힙 속성을 유지합니다.
if (largest !== i) {
[arr[i], arr[largest]] = [arr[largest], arr[i]];
heapify(arr, largest, n);
}
}
전위, 중위, 후위 순회
트리 순회는 부모노드를 언제 방문하는가에 따라 전위, 중위, 후위로 나뉜다.

전위순회는 루트 노드를 먼저 탐색하고, 자식 노드를 탐색하는 방식이다.

중위순회는 왼쪽 자식 노드를 탐색하고, 루트 노드를 탐색하고, 오른쪽 자식 노드를 탐색하는 방식이다.

후위순회는 왼쪽 자식 노드를 탐색하고, 오른쪽 자식 노드를 탐색하고, 루트 노드를 탐색하는 방식이다.
function preOrderTraversal(arr, i) {
if (i < arr.length) {
console.log(arr[i]);
preOrderTraversal(arr, 2 * i + 1);
preOrderTraversal(arr, 2 * i + 2);
}
}
function inOrderTraversal(arr, i) {
if (i < arr.length) {
inOrderTraversal(arr, 2 * i + 1);
console.log(arr[i]);
inOrderTraversal(arr, 2 * i + 2);
}
}
function postOrderTraversal(arr, i) {
if (i < arr.length) {
postOrderTraversal(arr, 2 * i + 1);
postOrderTraversal(arr, 2 * i + 2);
console.log(arr[i]);
}
}
코테에서 활용하기
클래스를 이용한 구현은 실제 코딩테스트 환경에서 사용하기 어려운 감이 있다.
또 공부를 하면서 정리하다보니 내용이 잡다해져서 코테에서 쓸 내용만 여기에 다시 추가로 정리해서 적으려고 한다.
최대한 필수적인 기능들을 이용해서, 배열을 이용하여, 완전이진트리 형태로 이진탐색트리와 힙 소트를 구현해보고자 한다.
배열을 이용한 완전이진트리
완전 이진트리의 배열을 통한 구현을 다시 보자
(https://wknphwqwtywjrfclmhjd.supabase.co/storage/v1/object/public/image/post/db16ae04-e335-4241-bfeb-179cd70f35d9/image.png)
사진출처
{kind=link}
배열의 0번 인덱스는 편의상 비워둔다.
배열의 1번 인덱스는 root 인덱스이다.
2번 인덱스는 2번째 깊이의 첫번째 요소,
3번 인덱스는 2번째 깊이의 두번째 요소이다.
위를 일반화하면, 2^(n-1)승 인덱스는 n번째 깊이의 첫번째 요소이다.
배열의 1번 인덱스의 왼쪽 자식은 2번 인덱스이다.
배열의 1번 인덱스의 오른쪽 자식은 3번 인덱스이다.
위를 일반화하면, 배열의 n번 인덱스의 왼쪽 자식은 2n번 인덱스,
배열의 n번 인덱스의 오른쪽 자식은 2n+1번 인덱스이다.
배열의 2번 인덱스의 부모는 1번 인덱스이다.
배열의 3번 인덱스의 부모는 1번 인덱스이다.
위를 일반화하면 배열의 n번 인덱스의 부모는 parseInt(n/2)번 인덱스이다.
이진 탐색 트리
위의 공식들을 이용하여
- 정렬이 완료된 배열을 입력받아
- 이진 탐색 트리의 형태로 표현한다.
이렇게 이미 정렬된 배열을 이진트리로 변환하는 이유는 중위순회, 후위순회와 같은 순회 문제를 풀기 위함이다.
가령 const input = [1, 2, 3, 4, 5, 6, 7, 8] 일 때,
목표하는 형태는
5
3 7
2 4 6 8
1
이다.
따라서 output은
[null, 5, 3, 7, 2, 4, 6, 8, 1]이 되어야 한다.
(작성중)
- 루트 노드를 지정한다.
- 배열의 길이가 홀수인 경우, 가장 가운데(
(n+1)/2) 요소가 루트 노드가 된다. - 배열의 길이가 짝수인 경우, 가운데의 두 요소 중 오른쪽 요소가 루트 노드가 된다.(오른쪽이 루트 노드가 됨 -> 배열이 왼쪽으로 편향됨 -> 배열이 왼쪽 하단부터 채워짐)
- 위를 요약하면, 루트 노드는
array[Math.floor(array.length/2)]이다. 트리의 1번에 삽입한다. - 루트 노드의 왼쪽 배열은 array.slice(0, Math.ceil(array.length/2)), 루트 노드의 오른쪽 배열은 array.slice(Math.ceil(array.length/2)+1) 이다.
- 해당 배열들에서 루트노드를 구해 왼쪽 자식은 트리의 12로, 오른쪽 자식은 트리의 12+1로 삽입한다.
위의 과정을 재귀적으로 반복한다.
- 배열의 길이가 홀수인 경우, 가장 가운데(
const inputArray = [1, 2, 3, 4, 5, 6, 7, 8];
const binaryTree = Array(inputArray.length + 1).fill(null);
const rootIndex = 1;
buildBinaryTree(inputArray, rootIndex);
console.log(binaryTree); //(9) [null, 5, 3, 7, 2, 4, 6, 8, 1]
function buildBinaryTree(array, treeIndex) {
// 부모 노드를 중앙에 위치한 요소로 지정합니다.
const midIndex = Math.floor(array.length / 2);
const parentNode = array[midIndex];
binaryTree[treeIndex] = parentNode;
// 왼쪽 자식 노드를 추가합니다.
const leftArray = array.slice(0, midIndex);
const leftChildIndex = treeIndex * 2;
if (leftChildIndex < binaryTree.length)
buildBinaryTree(leftArray, leftChildIndex);
// 오른쪽 자식 노드를 추가합니다.
const rightArray = array.slice(midIndex + 1);
const rightChildIndex = treeIndex * 2 + 1;
if (rightChildIndex < binaryTree.length)
buildBinaryTree(rightArray, rightChildIndex);
}
변수명은 chatGPT가 정해줬다.
input -> inputArray: 변수명을 보고 데이터 형식을 추측하기 쉬운 이름으로 변경했습니다.
tree -> binaryTree: 변수명을 봤을 때 이진트리(binary tree)를 떠올리기 쉽도록 변경했습니다.
treeIndex -> rootIndex: 해당 변수가 루트 노드의 인덱스를 나타내는 것으로 추측되어, 이름을 변경했습니다.
currentIndex -> midIndex: 해당 변수가 배열의 중앙 인덱스를 나타내는 것으로 추측되어, 이름을 변경했습니다.
currentElement -> parentNode: 해당 변수가 부모 노드를 나타내는 것으로 추측되어, 이름을 변경했습니다.
leftTreeIndex -> leftChildIndex, rightTreeIndex -> rightChildIndex: 해당 변수가 자식 노드의 인덱스를 나타내는 것으로 추측되어, 이름을 변경했습니다.
heap sort
힙 자료구조를 잘 설명해둔 블로그이다.
녘_님 블로그
앞으로 구현될 함수들은 순수 함수가 아니다. 이 말은 inputArray를 직접 조작하는 방식이라는 점이다.
어떤 값을 직접 조작하는데에는 class 안에 메서드를 선언하여 조작하는 것이 올바른 방향이며, 함수형 프로그래밍을 하려면 인풋을 받고 반환을 하고 반환된 값을 어떤 값으로 교체하는 것이 올바른 방향이다. 아래에 구현되는 내용은 실제 코딩테스트 환경에서 사용하기 쉽도록 클래스를 벗겨낸 구조라고 이해하는 것이 좋다.
Heapify
특정 배열을 최대 힙으로 만든다.
const inputArray = [8, 5, 3, 1, 9, 6, 0, 2, 7, 4];
//최초로 시작하기
for (let i = Math.floor(inputArray.length / 2); i >= 0; i--) {
maxHeapify(inputArray, i, inputArray.length);
}
function maxHeapify(arr, i, length) {
const left = i * 2 + 1;
const right = i * 2 + 2;
let parent = i;
if (left < length && arr[left] > arr[parent]) {
parent = left;
}
if (right < length && arr[right] > arr[parent]) {
parent = right;
}
if (i !== parent) {
[arr[parent], arr[i]] = [arr[i], arr[parent]];
maxHeapify(arr, parent, length);
}
}
console.log(inputArray); //[9, 8, 6, 7, 5, 3, 0, 2, 1, 4]
위 코드에서 Math.floor(arr.length / 2)는 마지막 레벨보다 한단 계 위의 레벨의 마지막 요소를 의미한다.

해당 위치부터 탐색을 시작하면, 결과적으로 모든 말단 노드들을 탐색하면서도 for문은 줄일 수 있다.
Math.floor(inputArray.length / 2)는 Heapify를 시작할 인덱스를 결정하기 위한 것입니다.
Max Heap에서는 트리의 마지막 레벨에 있는 노드들은 자식 노드가 없을 수 있습니다. 따라서 Heapify 과정을 수행해도 되지 않은 노드들을 건너뛰기 위해, Heapify를 시작할 인덱스를 결정하는 것입니다.
그러므로 Math.floor(inputArray.length / 2)는 루트 노드가 아니라 Heapify를 시작할 인덱스입니다. 루트 노드는 항상 배열의 첫 번째 요소에 위치하며, 이 코드에서는 루트 노드부터 시작하여 Heapify 과정을 거치면서 최종적으로 가장 큰 값이 루트 노드에 위치하게 됩니다.
아래는 chatGPT를 통해 가독성을 개선하고 변수명을 변경한 코드이다.
const heapify = (arr, i, length) => {
const leftChildIndex = i * 2 + 1;
const rightChildIndex = i * 2 + 2;
let maxIndex = i;
if (leftChildIndex < length && arr[leftChildIndex] > arr[maxIndex]) {
maxIndex = leftChildIndex;
}
if (rightChildIndex < length && arr[rightChildIndex] > arr[maxIndex]) {
maxIndex = rightChildIndex;
}
if (maxIndex !== i) {
[arr[maxIndex], arr[i]] = [arr[i], arr[maxIndex]];
heapify(arr, maxIndex, length);
}
};
const buildMaxHeap = (arr) => {
for (let i = Math.floor(arr.length / 2); i >= 0; i--) {
heapify(arr, i, arr.length);
}
};
const inputArray = [8, 5, 3, 1, 9, 6, 0, 2, 7, 4];
buildMaxHeap(inputArray);
console.log(inputArray);
Heappush
이때 최초 루트 인덱스를 0으로 잡았다는 점에 유의하자.
루트 인덱스가 0일 때, 어떤 인덱스 n의 부모 인덱스는 Math.floor((어떤인덱스-1)/2)이다.
(루트 인덱스가 1일 때에, 어떤 인덱스 n의 부모 인덱스는 Math.floor(어떤인덱스/2)이다.)
아래는 힙에 새로운 값을 추가하였을 때이다.
//삽입하기
const element = 12;
heappush(element, inputArray);
function heappush(element, arr) {
arr.push(element);
let crrIndex = arr.length - 1;
while (crrIndex) {
parentIndex = Math.floor((crrIndex - 1) / 2);
if (arr[crrIndex] >= arr[parentIndex]) {
[arr[crrIndex], arr[parentIndex]] = [arr[parentIndex], arr[crrIndex]];
crrIndex = parentIndex;
} else {
break;
}
}
}
console.log(inputArray); //[12, 9, 6, 7, 8, 3, 0, 2, 1, 4, 5]
Heappop
기본적인 로직은 힙의 가장 앞에서 어떤 값을 꺼낸 후, 남아있는 힙을 재정렬하는 것이다.
파이썬으로 구현하는 경우
list[0], list[-1] = list[-1], list[0]
max = list.pop()
heapify(list)
return max
위와 같이 'swap', 'pop', 'heaipfy' 순서가 된다.
이때 swap이 list[0], list[-1] = list[-1], list[0]로 진행되는데, 자바스크립트에서는 Array.prototype.at(-1) 으로 조회된 값은 Array에서 가져오는 것이 아니라 TypedArray라는 일종의 스냅샷으로 부터 조회하는 값이며, 이에 따라 스왑이 불가능하다.
개인적으로 array[array.length-1]로 접근하는 것을 싫어해서 아래와 같이 순서를 바꾸었다.
let lastElement = inputArray.pop();
[inputArray[0], lastElement] = [lastElement, inputArray[0]];
이후에 heap을 재정렬하면 되는데,
자식부터 거슬러 올라갔던 heapify보다 효율적인 방식은
부모 컴포넌트부터 내려오면서 더 큰 자식과 비교하는 것이다.
(자식컴포넌트부터 거슬러 올라가면 n log n 만큼의 시간 복잡도가 든다.
반면 부모 컴포넌트부터 내려오는 것은 log n 이다.)
아래는 부모 컴포넌트부터 (마지막 레벨 - 1)까지 while문으로 거슬러 내려가는 방식이다.
이때 자식이 undefined일 때에는 비교 연산을 할 때 0으로 처리된다는 점을 염두에 두자. 작성된 부등호의 순서를 바꾸거나 '=<'로 바꾸면 undefined라는 값이 리스트에 노출될 수도 있다. 아래의 예시는 이러한 점도 고려가 된 순서 및 등호이다.
let parentIndex = 0;
while (parentIndex <= Math.floor(arr.length / 2)) {
let biggerChildIndex = parentIndex * 2 + 1;
const rightChildIndex = parentIndex * 2 + 2;
if (arr[biggerChildIndex] < arr[rightChildIndex])
biggerChildIndex = rightChildIndex;
if (arr[parentIndex] < arr[biggerChildIndex]) {
[arr[parentIndex], arr[biggerChildIndex]] = [
arr[biggerChildIndex],
arr[parentIndex],
];
parentIndex = biggerChildIndex;
} else {
break;
}
}
구현된 Heappop은 아래와 같다. 언젠가부터 Heappop은 안 멋져
const max = heappop(inputArray);
function heappop(arr) {
let lastElement = arr.pop();
[arr[0], lastElement] = [lastElement, arr[0]];
let parentIndex = 0;
while (parentIndex <= Math.floor(arr.length / 2)) {
let biggerChildIndex = parentIndex * 2 + 1;
const rightChildIndex = parentIndex * 2 + 2;
if (arr[biggerChildIndex] < arr[rightChildIndex])
biggerChildIndex = rightChildIndex;
if (arr[parentIndex] < arr[biggerChildIndex]) {
[arr[parentIndex], arr[biggerChildIndex]] = [
arr[biggerChildIndex],
arr[parentIndex],
];
parentIndex = biggerChildIndex;
} else {
break;
}
}
return lastElement;
}
console.log(max); //12
console.log(inputArray); //[9, 8, 6, 7, 5, 3, 0, 2, 1, 4]
heappop(inputArray);
console.log(inputArray); //[8, 7, 6, 4, 5, 3, 0, 2, 1]
heappop(inputArray);
console.log(inputArray); //[7, 5, 6, 4, 1, 3, 0, 2]
heappop(inputArray);
console.log(inputArray); //[6, 5, 3, 4, 1, 2, 0]
전체코드
const inputArray = [8, 5, 3, 1, 9, 6, 0, 2, 7, 4];
//최초로 시작하기
for (let i = Math.floor(inputArray.length / 2); i >= 0; i--) {
maxHeapify(inputArray, i);
}
function maxHeapify(arr, i) {
const length = arr.length;
const left = i * 2 + 1;
const right = i * 2 + 2;
let parent = i;
if (left < length && arr[left] > arr[parent]) {
parent = left;
}
if (right < length && arr[right] > arr[parent]) {
parent = right;
}
if (i !== parent) {
[arr[parent], arr[i]] = [arr[i], arr[parent]];
maxHeapify(arr, parent);
}
}
//삽입하기
const element = 12;
heappush(element, inputArray);
function heappush(element, arr) {
arr.push(element);
let crrIndex = arr.length - 1;
while (crrIndex) {
parentIndex = Math.floor((crrIndex - 1) / 2);
if (arr[crrIndex] >= arr[parentIndex]) {
[arr[crrIndex], arr[parentIndex]] = [arr[parentIndex], arr[crrIndex]];
crrIndex = parentIndex;
} else {
break;
}
}
}
const max = heappop(inputArray);
function heappop(arr) {
let lastElement = arr.pop();
if (!arr.length) return lastElement;
[arr[0], lastElement] = [lastElement, arr[0]];
let parentIndex = 0;
while (parentIndex <= Math.floor(arr.length / 2)) {
let biggerChildIndex = parentIndex * 2 + 1;
const rightChildIndex = parentIndex * 2 + 2;
if (arr[biggerChildIndex] < arr[rightChildIndex])
biggerChildIndex = rightChildIndex;
if (arr[parentIndex] < arr[biggerChildIndex]) {
[arr[parentIndex], arr[biggerChildIndex]] = [
arr[biggerChildIndex],
arr[parentIndex],
];
parentIndex = biggerChildIndex;
} else {
break;
}
}
return lastElement;
}
코딩테스트 예제 (Shortest Job First)
위에서 구현한 코드들이 코딩테스트에서 어떻게 활용될 수 있는지, 실제로 작동되는지 테스트해보았다.
먼저 아래는 Array.prototype.sort()을 이용하여 '짧은 놈 먼저(SJF) 스케줄링'을 구현한 예시이다. 시간복잡도는 O(n^2)이다.
function solution(jobs) {
var answer = 0;
let sum = 0;
let waitingTime = 0
let indexSet = new Set()
jobs.sort((a,b) => {
return a[0]-b[0]
})
while (indexSet.size < jobs.length){
let minElement = [0, 1001]
let minIndex = -1
for (i = 0; i<jobs.length; i++){
if(indexSet.has(i)) continue
if(jobs[i][0] > sum) break
if(jobs[i][1] < minElement[1]) {
minElement = jobs[i]
minIndex = i
}
}
if(minIndex < 0) {
sum += 1
continue
}
sum += minElement[1]
waitingTime += sum-minElement[0]
indexSet.add(minIndex)
}
answer = Math.floor(waitingTime/jobs.length)
return answer;
}
Test 1 〉 통과 (10.66ms, 36.7MB)
Test 2 〉 통과 (321.45ms, 36.6MB)
Test 3 〉 통과 (51.33ms, 36.5MB)
Test 4 〉 통과 (30.87ms, 36.6MB)
Test 5 〉 통과 (6.40ms, 36.5MB)
Test 6 〉 통과 (0.27ms, 33.4MB)
Test 7 〉 통과 (4.99ms, 36.6MB)
Test 8 〉 통과 (4.63ms, 36.5MB)
Test 9 〉 통과 (0.94ms, 33.5MB)
Test 10 〉 통과 (6.70ms, 36.6MB)
Test 11 〉 통과 (0.22ms, 33.4MB)
Test 12 〉 통과 (0.24ms, 33.4MB)
Test 13 〉 통과 (0.21ms, 33.4MB)
Test 14 〉 통과 (0.19ms, 33.5MB)
Test 15 〉 통과 (0.19ms, 33.4MB)
Test 16 〉 통과 (0.12ms, 33.4MB)
Test 17 〉 통과 (0.09ms, 33.5MB)
Test 18 〉 통과 (0.10ms, 33.5MB)
Test 19 〉 통과 (0.10ms, 33.4MB)
Test 20 〉 통과 (0.11ms, 33.4MB)
Test 1 〉 통과 (6.35ms, 36.6MB)
Test 2 〉 통과 (5.67ms, 36.6MB)
Test 3 〉 통과 (5.09ms, 36.6MB)
Test 4 〉 통과 (5.05ms, 36.6MB)
Test 5 〉 통과 (6.07ms, 36.6MB)
Test 6 〉 통과 (0.22ms, 33.5MB)
Test 7 〉 통과 (4.72ms, 36.8MB)
Test 8 〉 통과 (4.53ms, 36.6MB)
Test 9 〉 통과 (0.90ms, 33.6MB)
Test 10 〉 통과 (6.89ms, 36.6MB)
Test 11 〉 통과 (0.20ms, 33.4MB)
Test 12 〉 통과 (0.20ms, 33.4MB)
Test 13 〉 통과 (0.21ms, 33.5MB)
Test 14 〉 통과 (0.19ms, 33.6MB)
Test 15 〉 통과 (0.19ms, 33.4MB)
Test 16 〉 통과 (0.09ms, 33.5MB)
Test 17 〉 통과 (0.09ms, 33.5MB)
Test 18 〉 통과 (0.12ms, 33.5MB)
Test 19 〉 통과 (0.09ms, 33.5MB)
Test 20 〉 통과 (0.07ms, 33.4MB)
아래는 배열을 위에서 구현한 heapsort의 '힙푸쉬'와 '힙팝'을 사용하여 푼 예시이다.
시간 복잡도는 O(N log N) 이다.
로직의 순서는
- jobs를 순회하면서 현재 시간 이하로 들어온 요청들을 꺼내서 heappush하기
- heappop으로 작업 하나 처리하기 / 만일 heap이 비어있다면 1분 대기하기
- 1과 2를 jobs와 heap이 모두 빌 때까지 반복하기
function solution(jobs) {
var answer = 0;
const length = jobs.length;
let elapsedTime = 0;
let waitingTime = 0;
jobs.sort((a, b) => {
return a[0] - b[0];
});
const heap = [];
while (heap.length || jobs.length) {
while (jobs.length) {
//만일 작업 목록에서 가장 먼저 들어온 요청의 시작시간이 elapsedTime보다 크면 push를 종료한다.
if (jobs[0][0] > elapsedTime) break;
//그렇지 않다면 작업 목록에서 가장 먼저 들어온 요청을 heap에 넣는다.
heap.push(jobs.shift());
let currentIndex = heap.length - 1;
while (currentIndex) {
const parentIndex = Math.floor((currentIndex - 1) / 2);
if (heap[currentIndex][1] <= heap[parentIndex][1]) {
[heap[currentIndex], heap[parentIndex]] = [
heap[parentIndex],
heap[currentIndex],
];
currentIndex = parentIndex;
} else {
break;
}
}
}
//heap에서 마지막 값을 꺼내고 minElement라고 임시로 이름을 붙여준다.
let minElement = heap.pop();
//만일 heap에 값이 남아있다면, heap의 첫번째 값과 minElement를 교환하고 정렬한다.
if (heap.length) {
[heap[0], minElement] = [minElement, heap[0]];
let parentIndex = 0;
while (parentIndex <= Math.floor(heap.length / 2)) {
let smallerChildIndex = parentIndex * 2 + 1;
if (smallerChildIndex >= heap.length) break;
const rightChildIndex = parentIndex * 2 + 2;
if (
!(rightChildIndex >= heap.length) &&
heap[smallerChildIndex][1] > heap[rightChildIndex][1]
)
smallerChildIndex = rightChildIndex;
if (heap[parentIndex][1] > heap[smallerChildIndex][1]) {
[heap[parentIndex], heap[smallerChildIndex]] = [
heap[smallerChildIndex],
heap[parentIndex],
];
parentIndex = smallerChildIndex;
} else {
break;
}
}
}
if (minElement) {
elapsedTime += minElement[1];
waitingTime += elapsedTime - minElement[0];
} else {
//만일 minElement값이 undefined라면 1분을 대기한다.
elapsedTime += 1;
}
}
answer = Math.floor(waitingTime / length);
return answer;
}
Test 1 〉 통과 (1.91ms, 34.6MB)
Test 2 〉 통과 (1.74ms, 34.5MB)
Test 3 〉 통과 (1.50ms, 34.4MB)
Test 4 〉 통과 (1.51ms, 34.2MB)
Test 5 〉 통과 (1.95ms, 34.5MB)
Test 6 〉 통과 (0.24ms, 33.7MB)
Test 7 〉 통과 (1.39ms, 34.2MB)
Test 8 〉 통과 (1.02ms, 34MB)
Test 9 〉 통과 (0.48ms, 33.7MB)
Test 10 〉 통과 (2.10ms, 34.6MB)
Test 11 〉 통과 (0.05ms, 33.6MB)
Test 12 〉 통과 (0.20ms, 33.7MB)
Test 13 〉 통과 (0.22ms, 33.6MB)
Test 14 〉 통과 (0.04ms, 33.6MB)
Test 15 〉 통과 (0.04ms, 33.6MB)
Test 16 〉 통과 (0.03ms, 33.6MB)
Test 17 〉 통과 (0.02ms, 33.7MB)
Test 18 〉 통과 (0.03ms, 33.7MB)
Test 19 〉 통과 (0.04ms, 33.3MB)
Test 20 〉 통과 (0.02ms, 33.3MB)