해당 글이 IBM의 예시를 잘 설명해주어서 참고하여 정리한다.
배경지식
Blocked
프로세스가 'Blocked' 됐다는 것은 작업이 중단되었음을 의미한다.
sleep- cpu를 할당받아도 사용할 수 없는 상태이거나,
wait- 프로세스가 자신이 요청한 이벤트가 처리되기를 기다리고 있는 상태이다.
(Suspended는 외부에서 resume을 해줘야 프로세스가 재개되지만,
Blocked는 조건이 맞지 않아 중단됐을 뿐, 조건이 충족되면(가령 이벤트가 완료되면) 프로세스가 재개된다.)
대표적인 Blocked 상태가 I/O burst(입출력 작업이 지속되는 것, 가령 하드디스크에서 정보를 읽기) 동안 프로세스가 Blocked 되는 것이다.
입출력은 생각보다 많은 시간이 걸린다. SSD나 인터넷 정보에서 발생하는 입출력은 약 50ms~100ms의 시간이 걸린다. 캐시 메모리에 접근하는데에는 3ns(0.000003ms)에 비교하면 프로세스의 성능에 절대적인 영향을 미친다고 볼 수 있다.
Blocking I/O

- 프로세스가 읽기 요청을 보낸다.
- 운영체제가 읽기를 시작한다.
- blocked : 프로세스는 아무런 작업을 하지 않는다. 운영체제도 아무런 작업을 하지 않는다.
- 운영체제가 읽기를 완료하고 데이터를 프로세스에게 넘겨준다. CPU의 제어권도 프로세스에게 넘겨준다.
- 프로세스의 작업이 재개된다.
딱 봐도 비효율적이다.
Non-blocking I/O

- 프로세스가 읽기 요청을 보낸다.
- 운영체제는 읽기를 시작하며 'EAGAIN'(에러(E)-나중에 다시(AGAIN) 요청하셈) 응답을 보낸다.
- 프로세스의 작업이 재개된다.
- 일정 시간 후 프로세스가 읽기 요청을 보낸다.
- 읽을 수 없는 상태이면 'EAGAIN'을 응답하고, 읽을 수 있는 상태이면 Data를 반환한다.
3-5) Data가 반환될 때까지 반복
Blocking 방식에 비해 CPU를 효율적을 활용한다.
하지만 프로세스가 주기적으로 읽기 요청을 다시 보낸다. 이를 Busy-Waiting 방식이라 한다.
Busy-Waiting 방식은
- Context Switching을 자주 발생시킨다. Context Switching은 매우 비싼 작업이다.
- 컨디션 검사에 많은 자원을 소모한다.
AIO : Async Non-blocking I/O

동기식이 순차적으로 처리된다면 Asynchronous 작업의 순서가 보장되지 않음을 의미한다. '순차적이지 않다' '순서가 보장되지 않는다'는 것은 '동시에 처리되는 것처럼 보인다'고 해석될 수 있다.(그렇게 보일 뿐, 동시에 처리하는 것은 아니다.)
비동기를 구현하는 법은 간단하다.
- 프로세스가 읽기를 요청한다.
- 운영체제는 읽기를 실행한 후, 프로세스에게 제어권을 넘긴다.
- 프로세스가 재개된다.
- 읽기가 완료되면 운영체제가 프로세스에게 인터럽트를 걸고 데이터를 넘겨준다.
- 프로세스가 재개된다.
I/O 멀티플렉싱
IBM은 I/O 멀티플렉싱을 "Async blocking I/O"로 분류했다.

shichao'note - I/O Models에 있는 다른 설명도 참조하자.
뭐가 됐든 간에, 중요한 것은 운영체제의 'Select'와 'Poll'이다.
운영체제는 여러개의 프로세스들의 요청을 받은 후,
처리가 완료되면 Select와 함께 인터럽트한 후, 데이터를 넘겨준다는 것이다.
그리고 이는 Node.js에서 사용하는 방식이기도 하다.
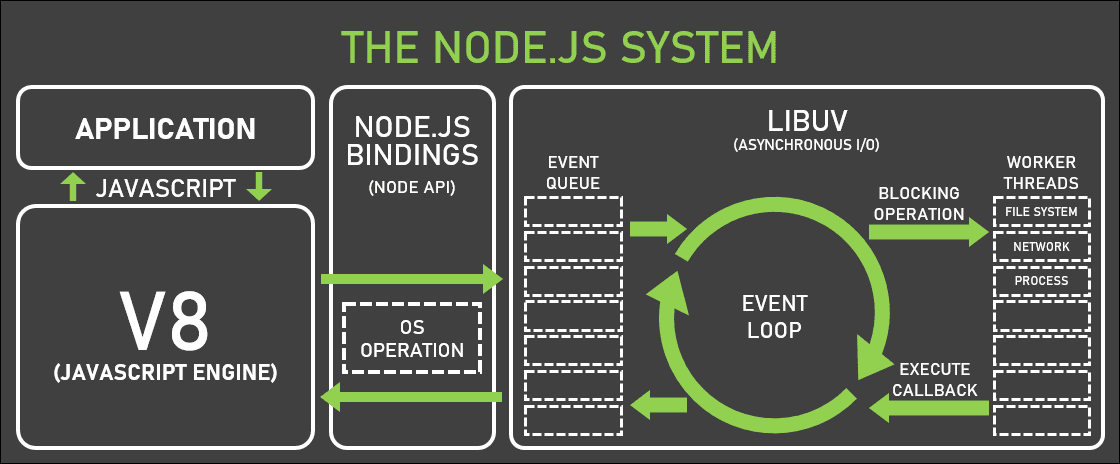
자바스크립트의 동작 원리 @graphicnovel
콜 스택 : 호출된 함수들을 Stack으로 push된다. 위에서 부터 실행하여 먼저 끝나는 함수가 먼저 pull된다.
콜백 큐 : 콜백 함수들은 Queue에 선입선출 한다. (먼저 발견된 함수가 먼저 실행된다.) Task Queue, Microtask Queue, Animation Frames 등 여러개의 Que가 있을 수 있다. (참조 1, 참조 2
이벤트 루프 : 큐를 Select하여, 콜백 함수를 꺼낸다. 꺼낸 콜백함수를 Call Stack에 push한다.
-
자바스크립트 엔진은 콜 스택의 인스트럭션을 실행하다가 새로운 콜백 함수를 만나면 콜백 큐에 넣어준다.
-
이벤트 루프는 콜백 큐의 함수가 자바스크립트 엔진에 처리될 수 있도록 콜 스택에 넣어 준다.
이러한 자바스크립트 엔진과 이벤트 루프의 상호작용을 통해, Node.JS와 크롬 브라우저는 싱글 스레드임에도 그 사이에 수 많은 Web API들을 비동기적으로 처리할 수 있게 된다.
스레드
프로세스는 작업의 단위. 프로세스 간에는 자원을 공유하지 않는다.
스레드는 실행 흐름의 단위. 부모의(프로세스의) 자원을 서로 공유할 수 있다.
멀티 스레드
하나의 프로세스를 다수의 실행단위(스레드)로 구분하여 자원은 공유하고, 수행 능력의 중복은 최소화하여 수행 능력을 향상 시키는 것. 내용 참조
장점 :
응답성 - 스레드의 일부분이 중단되어도 프로세스는 계속 진행하므로 사용자의 입장에서는 상호작용이 가능하다
경제성 - 자원의 공유로 인한 메모리/시스템 자원 소모가 줄어든다. 또 멀티 프로세스와 달리 멀티 스레드는 캐시를 공유하므로 context switching의 비용이 적다.
멀티프로세서 - 멀티 스레드를 각각의 다른 프로세서에서 병렬할 수 있어 멀티프로세서의 활용도의 측면에서 좋다.
단점 :
- 임계 영역 : DeadLock 등의 문제를 해결하기 위한 난이도가 높다. 뮤텍스, 세마포어 등의 동기화가 필요
- 병목 현상 : 동기화를 위해 뮤텍스, 세마포어 등을 적용하다보면 과도한 블라킹으로 병목현상이 발생한다.
- 단일 스레드보다 느린 성능 : context switching, 동기화 등의 이유로 단일 코어 단일 스레딩에 비해 성능이 느리다.
결과적으로 논블로킹-멀티스레딩을 구현하는 프로그래밍 난이도가 높다. 때문에 상대적으로 쉬운 멀티 프로세싱이 선호된다.
노드 JS의 스레드풀, 워커 스레드
Thread Pool : 노드Js에서 특정 동작을 수행할 때, 가령 암호화, 입출력, 압축 등은 멀티 스레드를 이용해 처리한다.
Worker Threads : 개발자가 직접 멀티스레드를 구현하여 사용할 수 있다. (노드12부터 지원)
Node JS의 특징
이벤트 기반 멀티 플렉싱 - 싱글 스레딩을 사용하는 Node JS는 다음의 특징을 가진다.
장점
- I/O 처리가 뛰어남 : 서버는 I/O처리가 많이 발생한다. Node js의 논 블로킹 방식으로 빠른 I/O처리가 발생하며, 전송에 있어서도 버퍼를 활용하기 보다는 데이터를 파이프라인 방식(Stream)으로 Chunk 단위로 보내는데에 특화되어 지연 없는 전송을 하게 된다.
- 비교적 쉬운 프로그래밍 (싱글 스레딩)
단점
- CPU 사용이 불리 : 타 언어로 작성된 서버에 비해 성능이 느리고, 멀티 스레딩 구현이 어려움 (영상처리 등은 CPU를 많이 먹는 작업)
- 에러 발생시의 대처 곤란 (싱글 스레딩)
Node js 쌩기초 문법
모듈
CommonJS
노드JS 출시 당시에 구현한 모듈 형식
module.export = { odd, even}
const { odd, even } = require('./var.js');
임포트 되는 순간 해당 파일, 함수를 실행하는 형식이다.
순차적으로 실행되며, 이미 해당 모듈이 실행중일 때에는 실행하지 않고 빈 객체를 반환한다. (즉, 순환 참조시에 빈 객체를 반환한다.)
동기적으로 처리 되기 때문에 조건부로 import하는 다이나믹 임포트가 가능하다.
ESM (ECMAScript Module)
export const odd
import odd from './var.mjs'
ES6(2015)에서 소개되었으며, Node js 12버전(2019년)에서 적용되었으므로 비교적 최근에 적용된 문법이다.
순차적으로, 동기적으로 import 되는 CommonJS 방식과 달리,
비동기적으로 동시에 import문이 먼저 평가된다.
- 파싱 : import된 모든 모듈에서 import문을 찾는다. 이후 이미 import된 모듈에 대한 import문을 건너 뛰어 하나의 종속성 트리를 만든다.
- 인스턴스화 : 트리의 아래에서 위로 인스턴스화를 진행하며 트리의 상위에서 export 구문을 연결한다.
- 평가 : 각 모듈의 실행 결과를 평가하고, 각 모듈을 '참조에 의한 전달'로 표현한다.
위와 같은 과정을 거치기 때문에 순환 참조가 일어나도 평가된 값을 갖게 된다.
import는 promise를 반환하며, 예외적으로 async키워드 없이도 await가 가능하다.
입출력
아래에서 부터 본격적으로 Node.js 교과서 개정 3판 내용이다.
const fs = require('fs')
fs는 파일 시스템으로 파일이나 디렉토리의 CRUD에 사용 가능하다.
fs.readFile('./readme.txt', (err, data) => {
if (err) {
throw err;
}
console.log(data);
console.log(data.toString());
});
(상식 : err를 반환할 때에 이를 catch하지 않으면 프로세스가 종료된다. catch되지 않은 err가 치명적일 수 있기에 그렇다.)
실제로는 비동기인 fs를 프라미스로 바꾸는 아래의 방식이 선호된다.
const fs = require('fs').promises;
fs.readFile('./readme.txt')
.then((data) => {
console.log(data);
console.log(data.toString());
})
.catch((err) => {
console.error(err);
});
const fs = require('fs');
fs.writeFile('./writeme.txt', '글이 입력됩니다', (err) => {
if (err) {
throw err;
}
fs.readFile('./writeme.txt', (err, data) => {
if (err) {
throw err;
}
console.log(data.toString()); //글이 입력됩니다.
});
});
입출력을 동기로 처리할 때에는 readFileSync()메서드를 쓴다.
const fs = require('fs');
console.log('시작');
let data = fs.readFileSync('./readme2.txt');
console.log('1번', data.toString());
data = fs.readFileSync('./readme2.txt');
console.log('2번', data.toString());
data = fs.readFileSync('./readme2.txt');
console.log('3번', data.toString());
console.log('끝');
readFile로 만들어진 데이터는 '버퍼'이다. 데이터를 한 번에 읽기 위해 데이터 용량만큼의 버퍼를 만들고 전달한다.
createReadStream()는 데이터를 chunk로 전달한다.
16비트 씩 chunk를 concat하여 스트링으로 만드는 예시이다.
const fs = require('fs');
const readStream = fs.createReadStream('./readme3.txt', { highWaterMark: 16 });
const data = [];
readStream.on('data', (chunk) => {
data.push(chunk);
console.log('data :', chunk, chunk.length);
});
readStream.on('end', () => {
console.log('end :', Buffer.concat(data).toString());
});
readStream.on('error', (err) => {
console.log('error :', err);
});
const fs = require('fs');
const writeStream = fs.createWriteStream('./writeme2.txt');
writeStream.on('finish', () => {
console.log('파일 쓰기 완료');
});
writeStream.write('이 글을 씁니다.
');
writeStream.write('한 번 더 씁니다.');
writeStream.end();
이벤트 에미터
Event Emitter, 즉 이벤트를 뿜뿜 방출하는 녀석이다.
const myEvent = new EventEmitter();
myEvent.on(이벤트명, 콜백) : 이벤트 이름과, 이벤트 발생시 실행할 함수를 연결한다. 이를 이벤트 리스닝이라 한다.
addListener(이벤트명, 콜백) : 상동
emit(이벤트명) : 리스닝 중인 이벤트를 호출한다.
once(이벤트명, 콜백): on과 같지만 여러번 호출해도 한 번만 실행된다.
removeAllListeners(이벤트명) : 이벤트에 연결된 모든 리스너를 제거한다.
removeListener(이벤트명, 리스너): 이벤트에 연결된 리스너를 제거한다.
off(이벤트명, 콜백) : 상동
listenerCount(이벤트명) : 이벤트에 연결된 갯수를 나열한다
const EventEmitter = require('events');
const myEvent = new EventEmitter();
myEvent.addListener('event1', () => {
console.log('이벤트 1');
});
myEvent.on('event2', () => {
console.log('이벤트 2');
});
myEvent.on('event2', () => {
console.log('이벤트 2 추가');
});
myEvent.once('event3', () => {
console.log('이벤트 3');
}); // 한 번만 실행됨
myEvent.emit('event1'); // 이벤트 호출
myEvent.emit('event2'); // 이벤트 호출
myEvent.emit('event3');
myEvent.emit('event3'); // 실행 안 됨
myEvent.on('event4', () => {
console.log('이벤트 4');
});
myEvent.removeAllListeners('event4');
myEvent.emit('event4'); // 실행 안 됨
const listener = () => {
console.log('이벤트 5');
};
myEvent.on('event5', listener);
myEvent.removeListener('event5', listener);
myEvent.emit('event5'); // 실행 안 됨
console.log(myEvent.listenerCount('event2'));
이벤트를 발생시킴으로서 옵저버 패턴을 구현할 수 있다.
한편 on으로 등록된 이벤트 리스너는 가비지 컬렉션되지 않는다. 조건에 맞으면 removeListener를 이용해 해당하는 이벤트 리스너를 제거해주자.
한 이벤트에미터당 10개까지 이벤트 리스너를 등록할 수 있다. setMaxListeners(n) 혹은 require('events').EventEmitter.defaultMaxListeners = n;의 방식으로 이벤트 리스너의 최대 갯수를 설정할 수 있다.
process.on('uncaughtException', 콜백함수)
앞서 언급했듯, catch되지 않은 에러가 발생하는 경우 uncaughtException를 발생시키고 프로세스를 종료한다. 하지만 만일 process에 'uncaughtException'이벤트를 처리하는 이벤트 리스너가 있으면 프로세스가 계속 진행된다. 단 프로세스가 예기치 못하게 진행될 가능성이 남아 있으므로, uncaughtException의 처리가 끝나면(가령 에러를 로깅하고 나면) process.exit() 등으로 종료시키는 것이 좋다.